The Kore.ai NLP engine uses Machine Learning, Fundamental Meaning, and Knowledge Graph (if any) models to match intents. All the three Kore.ai engines finally deliver their findings to the Kore.ai Ranking and Resolver component as either exact matches or probable matches. Ranking and Resolver determines the final winner of the entire NLP computation.
The Ranking & Resolver engine receives the outputs from the above engines and further processes them.
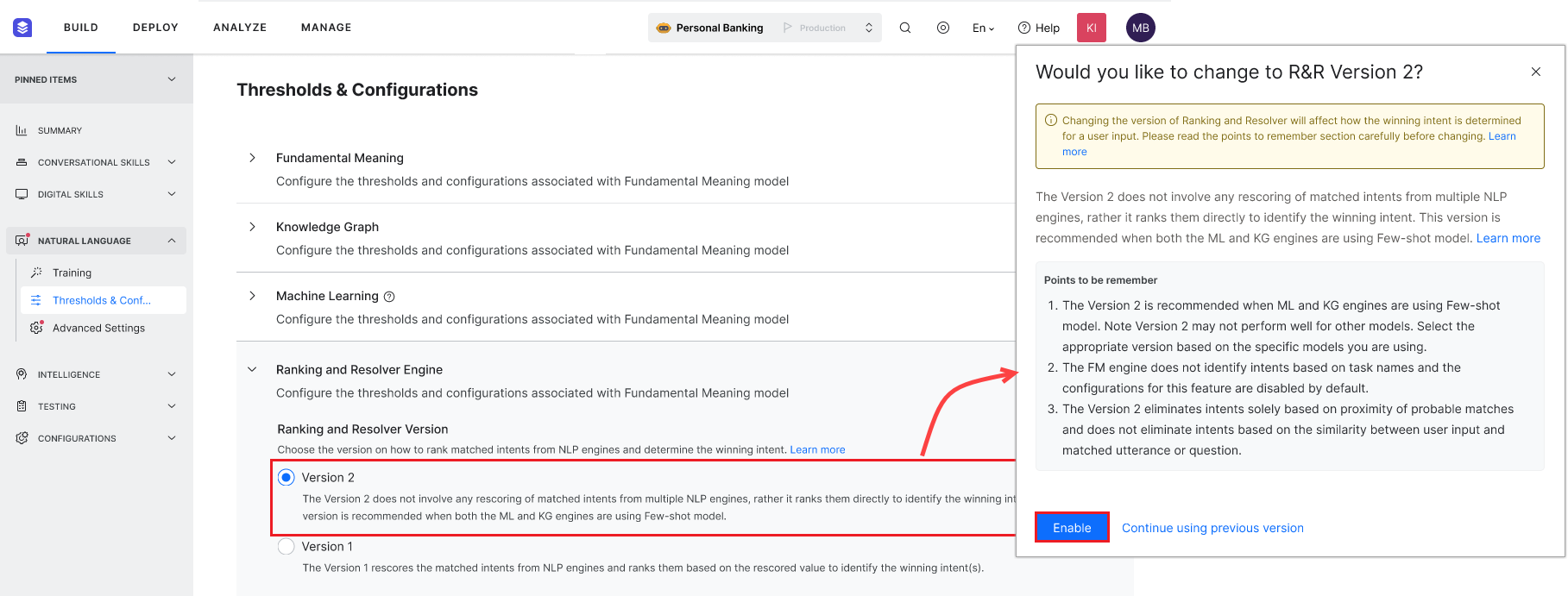
Notes on Ranking and Resolver Version 2With the introduction of Few-shot models in ML and KG engines, rescoring by Ranking & Resolver is no longer required for intent identification. Therefore, we have introduced a new version of Ranking & Resolver (Version 2) for Few-shot models that only ranks intents based on scores from ML and KG engines. The version significantly improves the accuracy of intent identification.You can choose one of the following versions of the Ranker and Resolver to define how to rank matched intents from NLP engines and determine the winning intent:
Important ConsiderationsBefore selecting this feature, please consider the following:
Enable Ranking & Resolver Version 2To enable Version 2 of R&R for the Few-shot Model, follow the steps below:
|
Ranking and Resolver Overview
Here is a short overview of the various parameters that the R&R engine works with:
- The output of the ML Engine: for a given utterance:
- Deterministic match: fuzzy score match of >= 95% match against user input.
- Probable matches: Confidence scores for each intent
- Top 5 utterances (from ML training dataset) of each intent whose confidence score is > threshold (default is 0.3)
- Top 5 utterances are found by ML engine which are close to the user inpu
- The output of the KG Engine:
- Deterministic Match: Fuzzy score if Deterministic (fuzzy match of >= 95% match against user input).
- Probable matches: Confidence scores of Questions that matched minimum threshold(>=50% match of path terms & >=60% word match)
- Synonyms matched, Nodes matched, Path terms matched, Class/Traits matched
- Original Question, Modified question(replaced with synonyms which matched)
- Alternate questions of each matched question
- The output of the FM Engine:
- Deterministic Match: Intents that matched deterministically (Pattern match or input is exactly the same as the task name)
- Probable matches: Partial label matches including synonyms.
Working Processes
The NLP engine uses a hybrid approach using Machine Learning, Fundamental Meaning, and Knowledge Graph (if the assistant has one) models to score the matching intents on relevance. The model classifies user utterances as either being Probable Matches or Definitive Matches.
Definitive Matches get high confidence scores and are assumed to be perfect matches for the user utterance. In published assistants , if user input matches with a single Definitive Match, the VA directly executes the task. If the utterances match with multiple Definitive Matches, they are sent as options for the end-user to choose one.
On the other hand, Probable Matches are intents that score reasonably well against the user input but do not inspire enough confidence to be termed as exact matches. Internally the system further classifies probable matches into good and unsure matches based on their scores. If the end-user utterances were generating probable matches in a published assistant, the VA sends these matches as Did you mean? suggestions for the end-user.
Based on the ranking and resolver, the winning intent between the engines is ascertained. If the Platform finds ambiguity, then an ambiguity dialog is initiated. The Platform initiates one of these two system dialogs when it cannot ascertain a single winning intent for a user utterance:
- Disambiguation Dialog: Initiated when there are more than one Definitive matches returned across engines. In this scenario, the VA asks the user to choose a Definitive match to execute. You can customize the message shown to the user from the NLP Standard Responses.
- Did You Mean Dialog: Initiated if the Ranking and Resolver returns more than one winner or the only winning intent is an FAQ whose KG engine score is between lower and upper thresholds. This dialog lets the user know that the VA found a match to an intent that it is not entirely sure about and would like the user to select to proceed further. In this scenario, the developer should identify these utterances and train the assistant further. You can customize the message shown to the user from the NLP Standard Responses.
Deciding the Winning Intent
The wining intent is decided by the Ranking & Resolver as follows:
- Definitive match(es) found:
- If any engine has found an Intent Definitively, that’s the winning Intent
- If more than one engine found different intents but Deterministically, then consider them as ambiguous and present the found intents as choices to the user to choose the intent which user felt is right.
- Probable match(es) found:
- Score each of the 5 utterances given by the ML engine and find the highest scoring utterance against each probable Intent.
- Score each of the alternate questions, modified questions given by the KG engine, and find the highest scoring question against each intent.
- Rank the scores and choose the Top scoring intent as the winning intent.
- If Topper and the immediate next intent are within the range of 2% then consider them as ambiguous.
- If a deterministic Intent is found, ignore all probable matches.
- If only FM or ML engines found an Intent but probable, that’s the winning intent.
- If only the KG engine found a probable intent and its score is > higher threshold(80%) then that’s the winning intent.
- If only the KG engine found a probable Intent and its score is >60% but <80% then that’s the winning intent, but since the confidence is low, show it as a suggestion (user will see “Did you mean”)
- If more than one probable intents were found,
Learn more about model scores and resolver.
Thresholds & Configuration
To set up Thresholds & Configuration for the Ranking and Resolver Engine, follow the below steps:
- Open the vA for which you want to configure thresholds.
- Select the Build tab from the top menu.
- From the left navigation click Natural Language > Thresholds & Configurations.
- The Ranking & Resolver Engine section allows you to set the threshold:
- Prefer Definitive Matches can be used to prioritize definitive matches over probable matches so that all the matches are considered for rescoring and the end-user gets to choose the right intent in case of any ambiguity. This setting is enabled by default and you can disable it. If enabled (default behavior), definitive matches will win and the probable matches would be discarded, in case of no definitive match, then probable matches would get rescored. If disabled, all the matches – definitive and probable, would be rescored.
- Rescoring of Intents can be turned off so that all the qualified intents from the different intent engines are assumed winning intents and are sent to the end-users to choose the required intent. If only one intent is qualified, then it is considered a winner, if more than one is qualified then the user will be presented with results for disambiguation.
- Negative Patterns When enabled, uses negative patterns to eliminate intents detected by Fundamental Meaning or Machine Learning models.
- Proximity of Probable Matches which defines the maximum difference to be allowed between top-scoring and immediate next probable intents to consider them as equally important. Before v7.3 of the Platform, this setting was under the Fundamental Meaning section.

Dependency Parsing Model
The Platform has two models for scoring intents by the Fundamental Meaning Engine and the Ranking & Resolver Engine:
- The first model predominantly relies on the presence of words, the position of words in the utterance, etc. to determine the intents and is scored solely by the Fundamental Meaning Engine. This is the default setting.
- The second model is based on the dependency matrix where the intent detection is based on the words, their relative position, and most importantly the dependency between the keywords in the sentence. Under this model, intents are scored by the Fundamental Meaning Engine and then rescored by the Ranking and Resolver Engine.
Dependency Parsing Model can be enabled and configured from the Ranking and Resolver section under Build > Natural Language > Training > Thresholds & Configurations.
| Note: This feature is supported only in select languages, see here for supported languages. |
The Dependency Parsing Model can be configured as follows:
- Minimum Match Score to define the minimum score to qualify an intent as a probable match. It can be set to a value between 0.0 to 1.0 with the default set to 0.5.
- Advanced Configurations are used to customize the model by changing the weights and scores associated with various parameters. This opens a JSON editor where you can enter the valid code. You can click the restore to default configurations to get the default threshold settings in a JSON structure, you can change the settings provided you are aware of the consequences.


NLP Detection
The Natural Language Analysis will result in the following scenarios, which will be discussed below:
- NLP Analysis identifying a Definitive match with FM or ML or KG engines.
- NLP Analysis with multiple engines returning a probable match and selecting a single match.
- NLP Analysis with multiple engines returning a probable match and resolver returning multiple results.
- NLP Analysis with no match.
To understand NLP detection, let us use the example of a Travel Planning assistant with the following details:
- The assistant consists of several dialog tasks and its intents are trained with Synonyms, Patterns, and ML utterances.
- The Knowledge Graph is defined with 86 FAQs distributed across 4 top-level terms.
Scenario 1 – FM Identifying a Definitive Match
In this example, the following occurs:
- The Fundamental Meaning (FM) model identified the utterance as a Definitive match.
- The Machine Learning (ML) model did not identify a match.
- An intent using the same verb form has been eliminated. , so the FM model termed it a Definitive match.
- The Knowledge Graph engine has also considered the utterance as a Probable match to the question: How do I book my flight?.

Scenario 2 – ML Identifying a Definitive Match
In this example, both the FM and ML models show this intent as a match – Definitive and Probable respectively.

Scenario 3 – KG Identifying a Definitive Match
This scenario can be explained as follows:
- The user utterance is How do I book a flight?
- The user utterance contains all the terms required to match it to the How do I book my flight question.
- As 100% path term matched the path was qualified. As part of confidence scoring, the terms in the user query are similar to that of the actual Knowledge Graph question. Thus, it returns a score of 100. As such, the intent is marked as a Definitive match and selected.
- The ML and FM models also found a Probable Match to the Book Flight intent.
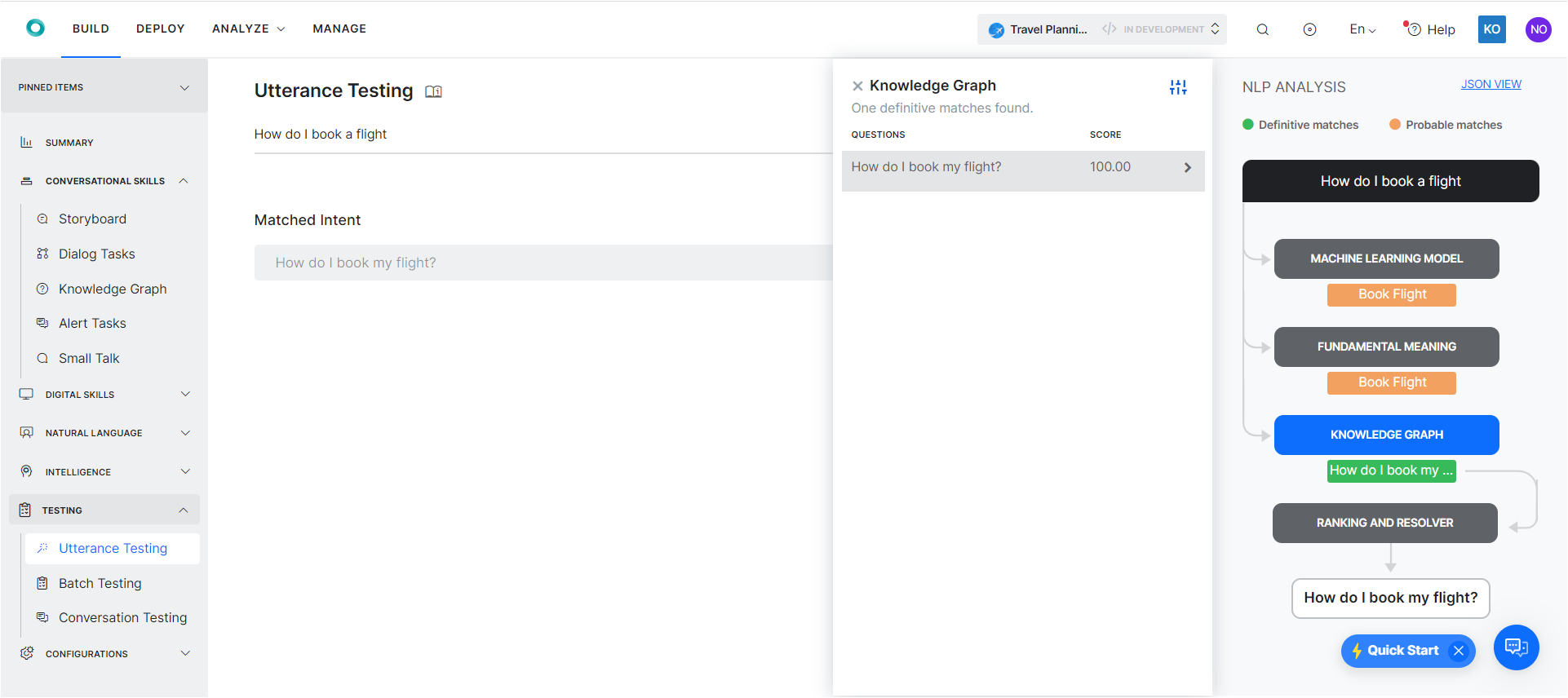
Scenario 4 – Multiple Engines Returning a Probable Match
In this scenario, we can see that:
- All the 3 engines returned a probable match and no definitive match.
- Each engine has found one probable match. All probable matches identified are re-ranked in the Ranking and Resolver.
- The Ranking and Resolver component returned the highest score for the single match (Task name – Book Flight ) from the FM engine. The score for this match is highest, which is why it is the winning intent that is presented to the user.
- Though most of the keywords in the user utterance map to the keywords in the KG query, still this is not a definitive match because the number of path terms is not 100%.

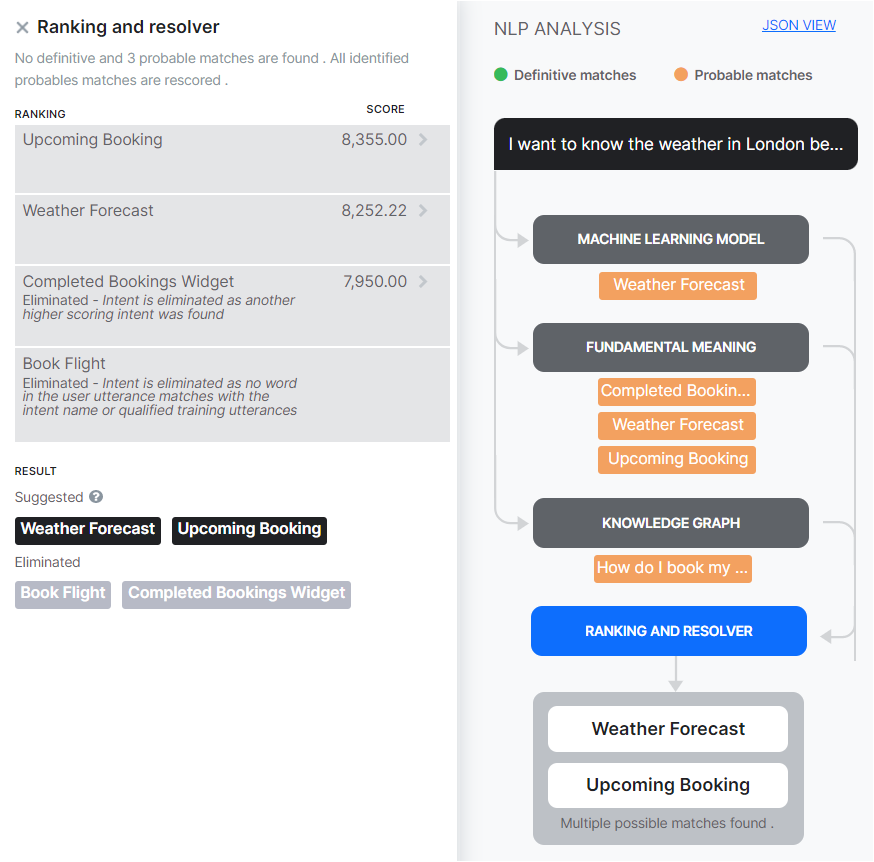
Scenario 5 – Resolver Returning Multiple Results
This example shows the following:
- The FM Engine detected probable matches. The ML and KG engines each returned one probable match.
- Ranking and resolver found the 2 queries with close scores. .
- Both intents are selected and presented to the user as Did-you-mean.
- Both the intents were selected as terms in both matches and the score for both the paths is more than 60%.
Scenario 6 – No Match Identified
In this final example, there is no match for the utterance:
- None of the engines could identify any trained intent or Knowledge Graph intent.
- The default intent is triggered.
