The Dynamic Conversations features boost your virtual assistant’s performance with LLM-powered runtime features designed to streamline development and reduce time and effort. By default, all the features are disabled. To enable the feature, select the model, prompt, and toggle the status to enable it. You can select another supported model for a feature if you have configured multiple models. You can also change the model, its prompts, and its settings.
Steps to enable the feature:
- Navigate to Build > Natural Language > Generative AI & LLM > Dynamic Conversations.

- Select the Model and the Prompt from the drop-down list for a feature.
- Turn on the Status toggle. The success message is displayed.
Change Settings for a Model
Click the option below to see the steps:
Change Settings for a Pre-built Model
You can change the selected model’s settings if required. In most cases, the default settings work fine.
Follow these steps:
- Go to Build > Natural Language > Generative AI & LLM > Dynamic Conversations.
- Hover over the feature to view the Advance Setting (gear) icon.

- Click the Advance Setting. The Advance Settings dialog box is displayed.

Adjusting the settings allows you to fine-tune the model’s behavior to meet your needs. The default settings work fine for most cases. You can tweak the settings and find the right balance for your use case. A few settings are common in the features, and a few are feature-specific:

{kind=link}
-
- Model: The selected model for which the settings are displayed.
- Instructions or Context: Add feature/use case-specific instructions or context to guide the model.
- Temperature: The setting controls the randomness of the model’s output. A higher temperature, like 0.8 or above, can result in unexpected, creative, and less relevant responses. On the other hand, a lower temperature, like 0.5 or below, makes the output more focused and relevant.
- Max Tokens: It indicates the total number of tokens used in the API call to the model. It affects the cost and the time taken to receive a response. A token can be as short as one character or as long as one word, depending on the text.
- Number of Previous User Inputs: Indicates how many previous user messages should be sent to the model as context for rephrasing the response sent through the respective node. For example, 5 means that the previous 5 responses are sent as context.
- Additional Instructions: Add specific instructions on how prompts should be rephrased. You can create a persona, ask it to rephrase in a particular tone, etc.
- Similarity Threshold: The Similarity Threshold is applicable for the Answer from Docs feature. This threshold refers to the similarity between the user utterance and the document chunks. The platform shortlists all chunks that are above the threshold and sends these chunks to the LLMs to auto-generate the responses. Define a suitable threshold that works best for your use case. Setting a higher threshold limits the number of chunks and may not generate any result. Setting a lower threshold might qualify too many chunks and might dilute the response.
Change Settings for a Custom Model
For a custom model, you can only change the post-processor script to adjust the actual response with the expected response.
In the case of GenAI Node only, you can change the Exit Scenario Key-Value, Virtual Assistance Response Key, and a post-processor script.
Follow these steps:
- Go to Build > Natural Language > Generative AI & LLM > Dynamic Conversations.
- Hover over the feature to view the Setting (gear) icon.

- Click Edit. The Actual Response is displayed.

- Click Configure. The Post Processor Script is displayed.

- Modify the script and click Save & Test. The Response is displayed.

- Click Save.
- (Only for GenAI Node) Enter the Exit Scenario Key-Value and Virtual Assistance Response Key fields. Click Save.
The Exit Scenario Key-Value fields help identify when to end the interaction with the GenAI model and return to the dialog flow. A Virtual Assistance Response Key is available in the response payload to display the VA’s response to the user.

Model and Feature Support Matrix
The following table displays the Dynamic Conversation features and the supported models.
(✅ Supported | ❌ Not Supported)
| Model | GenAI Node | Answer From Documents | GenAI Prompt | Rephrase Dialog Responses | Zero-shot ML Model | Repeat Responses | Rephrase User Query |
| Azure OpenAI – GPT 3.5 Turbo | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Azure OpenAI – GPT 4 Turbo, GPT 4o, and GPT-4o mini* | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| OpenAI – GPT 3.5 Turbo | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI – GPT 4 | ✅ | ✅ | ✅ | ✅ | ✅^ | ✅ | ❌ |
| OpenAI – GPT 4 Turbo, GPT 4o, and GPT-4o mini* | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Provider’s New LLM** | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Custom LLM | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Amazon Bedrock | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ |
| Kore.ai XO GPT | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ |
* The OpenAI GPT-4o mini and Azure OpenAI GPT-4o mini do not include system prompts, but they can be used with custom prompts.
** To use the Provider’s New LLM, you must create a custom prompt as system prompts are unavailable.
Feature Details
GenAI Node
When enabled, this feature lets you add an GenAI Node to Dialog Tasks. This node allows you to collect Entities from end-users in a free-flowing conversation (in the selected English/Non-English Bot Language) using LLM and Generative AI in the background. You can define the entities to be collected as well as rules & scenarios in English and Non-English Bot languages. You can configure node properties just like any other node. You can also use the GenAI Node across Dialog Tasks.

Usage
When creating or editing a Dialog Task that’s created manually or auto-generated, you can find a node called GenAI Node within your nodes list.
When this feature is disabled, the node is unavailable within the Dialog Builder. Learn more.
Answer From Documents
This feature leverages a Large Language Model (LLM) and Generative AI models from OpenAI to generate answers for FAQs by processing uploaded documents in an unstructured PDF format and user queries.

Usage
After redacting personally identifiable information, the uploaded documents and the end-user queries are shared with OpenAI to curate the answers.
Once you meet the prerequisites and enable the feature:
- You should upload the PDF document(s) to be shared with the third-party system (OpenAI). You can upload a maximum of 10 documents with a size of not more than 5 MB.
- The uploaded documents are listed under the Answer from Documents section with the following details:
- Upload Name
- Uploaded by
- Uploaded on
- Status (Active/Inactive)
- Actions (View and Delete File)
- A good practice is to test the answer generation by asking the VA a question directly related to the contents of your uploaded documents. Learn more.
- You can view, delete, and disable the uploaded documents.
- The VA provides answers only from uploaded documents that are active, whereas disabled documents are ignored.
If the feature is disabled, you won’t be able to send queries to LLMs as a fallback. Learn more.
GenAI Prompt
This feature lets you define custom user prompts based on the conversation context and the response from the LLMs. You can define the subsequent conversation flow by selecting a specific AI model, tweaking its settings, and previewing the response for the prompt.
Usage
- When building the Dialog Flow, click the “+” button, and select the GenAI Prompt node.

- Configuring the Component Properties in the following sections helps set up the node:
- General Settings: Provide Name and Display Name for the node and write your own OpenAI Prompt.
- Advanced Settings: Fine-tune the model’s behavior and tweak its settings as required for the following:
- Model
- System Context
- Temperature
- Max Tokens
- Advanced Controls: Select the maximum wait time (Timeout) to receive a response from the LLM and the bot’s response (Timeout Error Handling) when a timeout error occurs.
- When you add custom tags to the current message, user profile, and session under Instance Properties, you can build custom profiles for the bot conversation. .
- Configuring node connections on an instance lets you define the connection rules for the conversation using transition conditions. This lets the conversation follow specific paths based on the user’s input.
If this feature is disabled, you cannot configure the ML model to build custom prompts using OpenAI for different use cases. Learn more.
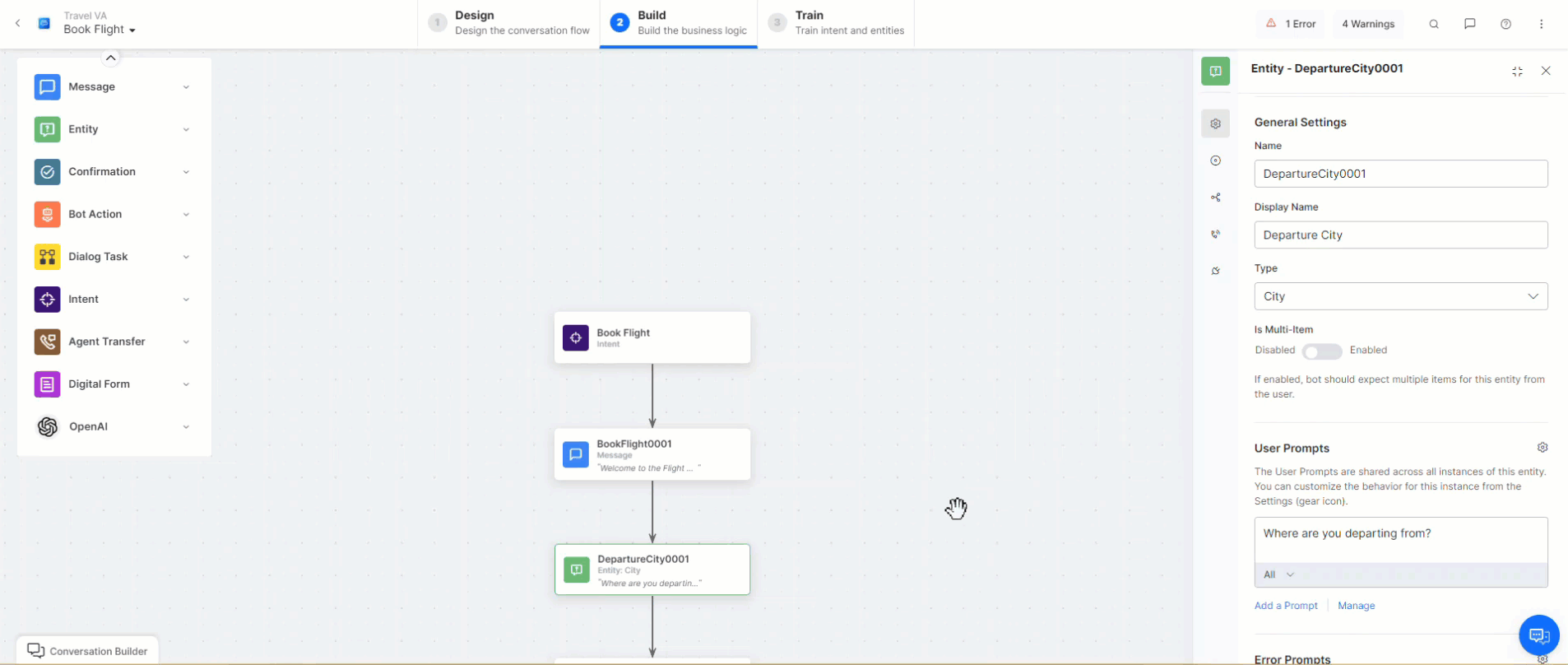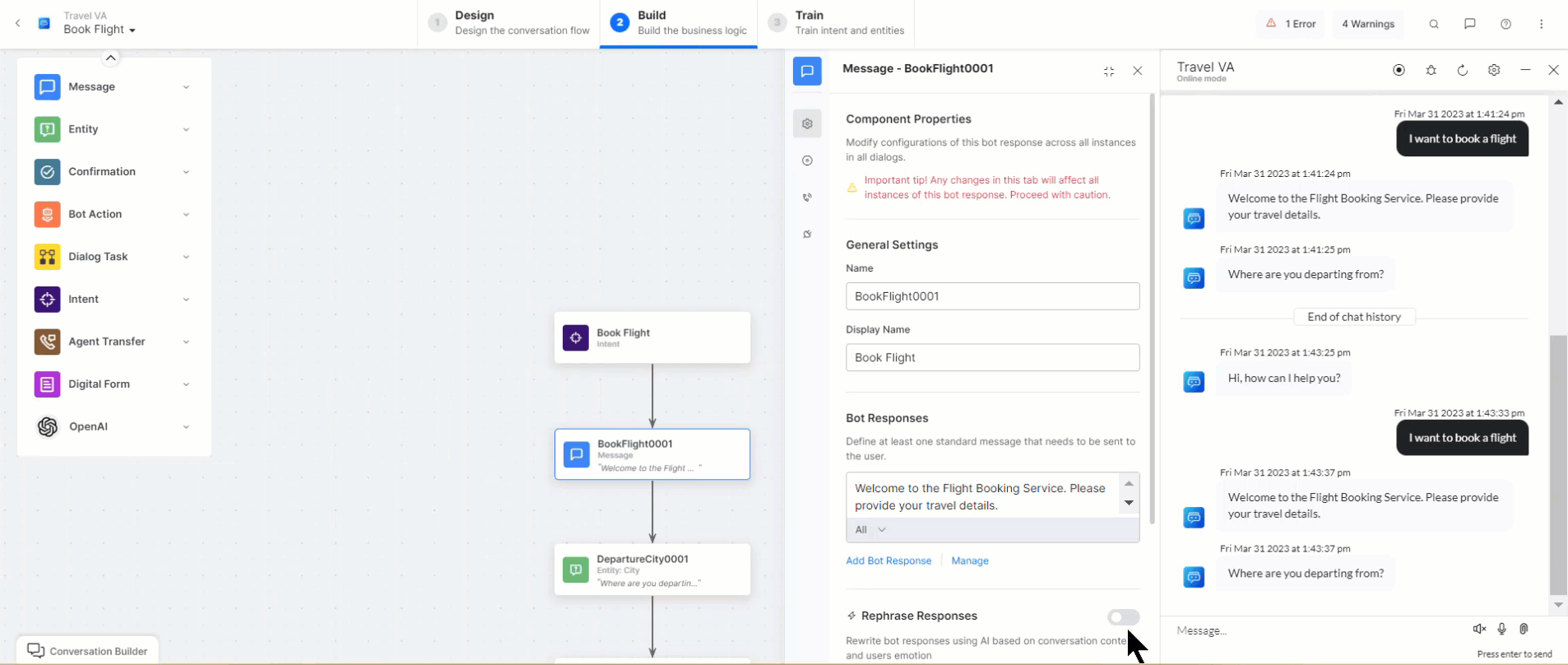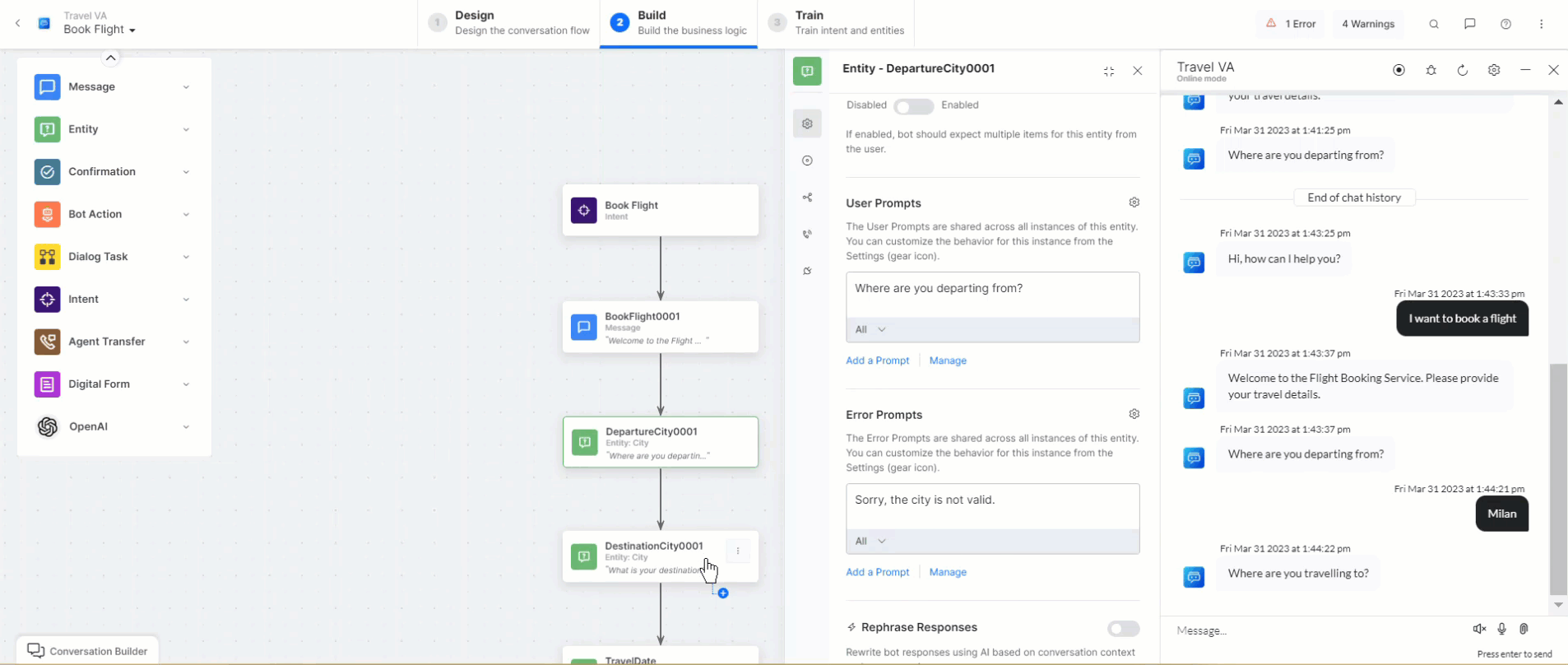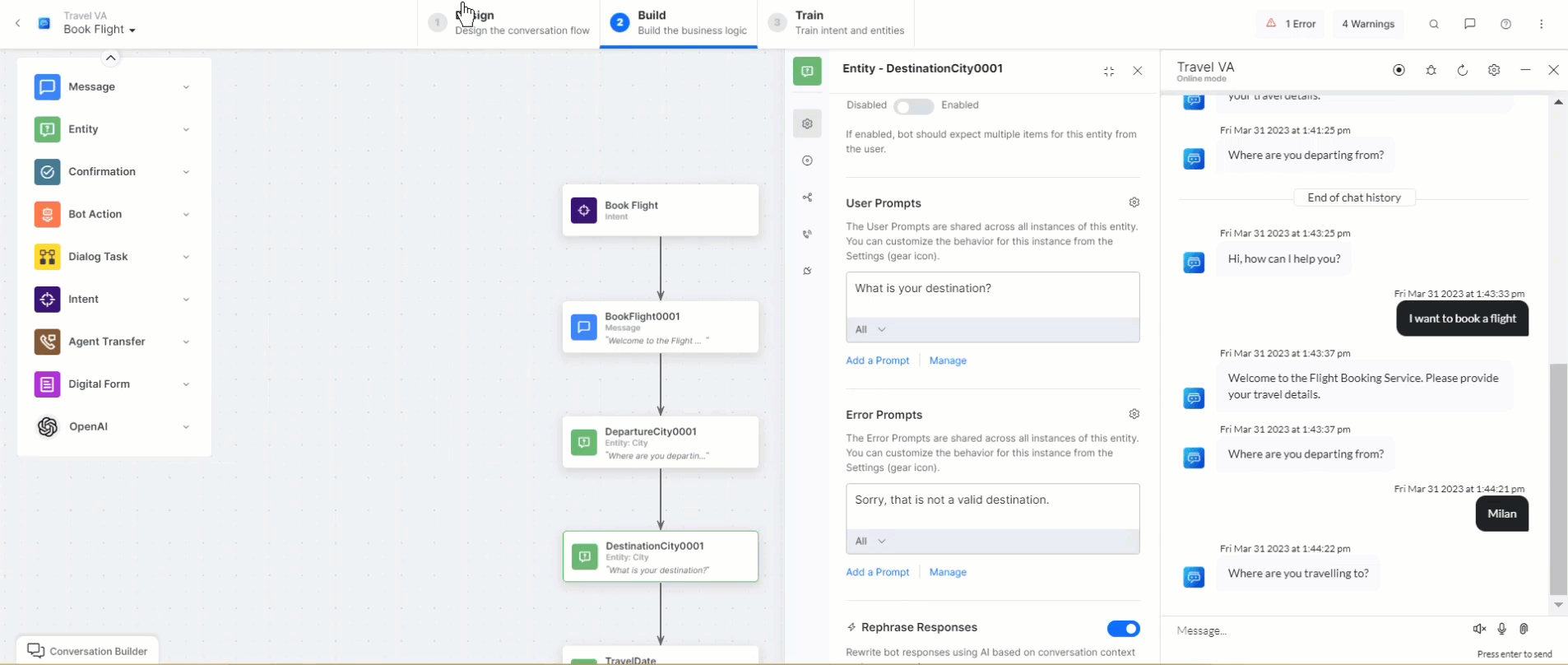
Rephrase Dialog Responses
This feature sends all User Prompts, Error Prompts, and Bot Responses to the Generative AI along with the conversation context, which depends on the configured number of user inputs. Responses are rephrased in English or the selected Non-English Bot Language based on the context and user emotion, providing a more empathetic, natural, and contextual conversation experience to the end-user. You can give instructions (additional instructions) in English or any other bot language you select.
Usage
When configuring a Message, Entity, or Confirmation node, you can enable the Rephrase Response feature (disabled by default). This lets you set the number of user inputs sent to OpenAI/Anthropic Claude-1 based on the selected model as context for rephrasing the response sent through the node. You can choose between 0 and 5, where 0 means that no previous input is considered, while 5 means that the previous. 5 responses are sent as context.
When this feature is disabled, the Rephrase Response section is not visible within your node’s Component Properties.
Zero-shot ML Model
Usage
This feature helps the ML Engine identify the relevant intents from user utterances based on semantic similarity. By identifying the logical intent during run time, this feature eliminates the need for training data. The Zero-shot ML model requires well-defined intents to work well. This training approach is well-suited for virtual assistants with relatively fewer intents and distinct use cases.
For the Zero-shot model feature, the XO Platform offers two template prompts for every supported model of Open AI and Azure Open AI. The template prompts are “Default” and “Zero-Shot-V2”. The “Zero-Shot-V2” is the advanced version of the “Default” template and is selected by default as you select the model. You can import both templates and create a custom prompt using them.
Conversation History Length
Note: The conversation history length applies only to zero-shot v2 prompts.
This setting allows you to specify the number of recent messages sent to the LLM as context for the user query rephrasing feature. These messages include both user messages and virtual assistant (VA) messages. The default value is 10. However, the number of messages sent is limited to the session’s conversation history, even if your set value is higher. You can access the Conversation History Length from the Advanced Settings.

Before performing utterance testing, the user selects the Zero-shot Model Network Type. During utterance testing, the user provides a more descriptive input with a subject, object, and nouns. Once the test runs, the system identifies the most logical intent as the definitive match by comparing the following:
- User utterance input
- Intent names
The identified intent is then displayed as the matched intent.
If this feature is disabled, the system won’t identify and display the logical and matched intent during utterance testing. Learn more.
Repeat Responses
This feature uses LLM to reiterate the recent bot responses when the Repeat Response event is triggered. Bot developers can enable the event and customize the trigger conditions. This empowers end-users to ask the bot to repeat its recent responses at any point during the conversation. Currently, this event is supported for IVR, Audiocodes, and Twilio Voice channels. Learn more.
Rephrase User Query
This feature uses the Kore.ai XO GPT Model. This model helps improve intent detection and entity extraction by enriching the user query with relevant details from the ongoing user conversation.
When a user intent and entity are split across multiple utterances or through the conversation, the feature enriches the user query by rephrasing the user’s multiple queries during runtime. This enriched user query contains all the conversation details so the bot can understand the actual meaning behind a user’s utterance. This enriched user query is fed to the natural language, improving accuracy by improving intent identification and entity extraction.
Usage
The LLM rephrases the query using one of the following methods depending on the scenario:
Completeness: The user query should be complete based on the conversation context so that the NLP can identify the right intent. If the user query is incomplete, the system urges the user to rephrase with more information.
For example:
User: What is the weather forecast for New York tomorrow?
Bot: It will be Sunny, with temperature ranging between 30 – 35 degrees Celsius.
User: How about Orlando?
Bot: Sorry, I cannot understand. Can you please rephrase?
The query should be completed as “How about the weather forecast in Orlando tomorrow?”.
Co-referencing: Coreference arises when multiple expressions or queries within text pertain to a common entity. In cases where a user’s query demonstrates incomplete coreference, the system prompts the user to rephrase the query with additional information. This enhances NLP’s ability to discern the correct intent and entities involved.
For example:
User: I’ve been experiencing a persistent headache for the past week.
Bot: I’m sorry to hear that. Have you been taking any medication for it?
User: Yes, I’ve been taking ibuprofen, but it doesn’t seem to help much.
Bot: I see. How often do you take ibuprofen?
User: I take it every six hours
Bot: I don’t understand. Can you tell me how often you take ibuprofen?
The co-reference in the user query should be expanded for NLP to identify the right intent and entities. The co-reference should be expanded as “I take ibuprofen every six hours”.
Completeness and Co-referencing: The following example illustrates completeness and co-referencing issues with the user’s input which triggers rephrasing.
For example:
User: I want to apply for a personal loan.
Bot: Sure, I can help you. You’re eligible to take a personal loan of up to 20,000$.
User: How about a Home loan?
Bot: You’re eligible to apply for a home loan as well. You can avail up to 100,000$.
User: What about the interest rates of both loans?
The co-reference and the query have to be completed as “What is the interest rate of personal loan and home loan?
Conversation History Length
This setting allows you to specify the number of recent messages sent to the Kore.ai XO GPT model as context for the user query rephrasing feature. These messages include both user messages and virtual assistant (VA) messages. The default value is 10. However, the number of messages sent is limited to the session’s conversation history, even if your set value is higher.
You can access the Conversation History Length from Repharse User Query > Advanced Settings.

Few-shot ML Model
The Few-shot model uses Kore Ai’s hosted embeddings to train virtual assistants based on intent names and training utterances. The model identifies the intents based on semantic similarity between user and training utterances.
Usage
Before performing utterance testing, the user selects the Few-Shot Model (Kore.ai Hosted Embeddings) network type.
During utterance testing, the user provides a more descriptive intent name with a subject, object, and nouns, as well as the training utterances. Once the test runs, the system identifies the most logical intent as the definitive match based on the following:
- The default configuration settings
- User utterance input
- Intent names
If this feature is disabled, the system won’t identify and display the logically matched intent during utterance testing. Learn more.