CSVまたはJSONファイルでナレッジグラフを構築し、ボットにアップロードすることができます。同様に、既存のナレッジグラフをCSVまたはJSONにエクスポートすることができます。ナレッジグラフをエクスポートすると、スプレッドシートで編集したり、他のボットにインポートしたりするのに役立ちます。最大50kのFAQを最大20kノードに分散させるというプラットフォームの制限があります。この数を超えるファイルのインポートは拒否されます。
ナレッジグラフのインポート
- KGをインポートしたいボットを開き、構築タブを選択します。
- 左側ペインで、会話スキル -> ナレッジグラフをクリックします。
- インポートオプションは、それぞれのナレッジグラフにあります。

- インポートをクリックします。
- インポートダイアログボックスで、以下のいずれかを実行します。
- ナレッジグラフをゼロから作成する場合は、続行をクリックします。(または)
- 既存のナレッジグラフがある場合は、必ず、CSVまたはJSONファイルにバックアップを取ってから、続行します。
メモ:ナレッジグラフをインポートしてもそれは更新されず、既存のナレッジグラフ全体が置き換わります。
- 「インポート」ウィンドウにファイルをドラッグアンドドロップするか、あるいはブラウズをクリックして、ファイルを探します。
- 次へをクリックして、インポートを開始します。
- インポートが完了すると、ダイアログボックスに成功のメッセージが表示されます。完了をクリックします。
- 階層はナレッジグラフに表示され、同じものを編集およびトレーニングすることができます。
ナレッジグラフのエクスポート
ナレッジグラフをエクスポートするには、以下の手順に従います。
- 左側ペインで、会話スキル -> ナレッジグラフをクリックします。
- エクスポートオプションは、それぞれのナレッジグラフにあります。
- 希望する形式に従って、JSONのエクスポートまたはCSVのエクスポートをクリックします。
- ナレッジグラフファイルがマシンにダウンロードされます。
ナレッジグラフの作成
プラットフォームのUIからナレッジグラフを作成するのではなく、スプレッドシートのような希望するエディターで、あるいはJSONファイルとして作業することができます。このプラットフォームでは、スプレッドシートまたはJSONでナレッジグラフを作成し、それを使用してボットにインポートするオプションが提供されています。インポートするには、以下の手順に従います。
- サンプルのCSVまたはJSONファイルをダウンロードします。これらのサンプルファイルは、空のナレッジグラフからもダウンロードすることができます。
- 質問、応答、同義語などに対応する行を追加して、ファイルを編集します。
- ファイルをボットにインポートします。
CSVファイルから
ナレッジグラフは、ボットからダウンロードできるサンプルのスプレッドシートを使用して作成することができます。ナレッジグラフを頻繁に変更することが予想される場合、アプリケーションのUIと比較して一括更新が容易にできるので、スプレッドシートで作成することをお勧めします。以下の手順に従って、スプレッドシートでナレッジグラフを構築します。
サンプルCSVファイルのダウンロード
- 左側ペインで、ボットタスク > ナレッジグラフをクリックします。
- インポートオプションは、それぞれのナレッジグラフにあります。
- 続行する前に、ナレッジグラフを バックアップするように指示されています。バックアップのCSVまたはJSON形式を選択します。
- バックアップ後、続行をクリックします。
- 対応するダイアログボックスで、サンプルCSVをクリックします。CSVファイルがローカルコンピュータにダウンロードされます。
Build the Knowledge Graph in a CSV
The format for the CSV file includes details regarding alternate answers, extended responses, and advanced responses.
- The following types of entries are supported:
- Faq – The leaf level nodes with questions and answers.
- Node – For node/tags, traits, preconditions, and output context.
- Synonyms
- KG Params
- Traits
- Each of the above categories needs to be preceded by the appropriate header.
- The header helps identify the new vs old versions of the JSON file by the platform.
The following is the detailed information for each section and the content expected for each.
FAQ
This contains the actual questions and answers along with the alternate questions, answers, and extended answers.

Following are the column-wise details that can be given:
- Faq – Mandatory entry in the header, must be left blank in the following rows.
- Que ID – The Question ID is auto-generated by the platform. This field uniquely identifies the FAQs and it should not be added or edited manually. Leave this field blank if you are adding a new FAQ. Do not alter the value of this field if you are updating an existing FAQ. Do not manually add any data in this field.
- Path – To which the FAQ belongs
- Mandatory node names must be prefixed with ** and organizer nodes with !!
- Primary Question – The actual question user might ask: When left blank, the entry in the Answer column is considered as the alternative answer to the previous primary question.
- Alternate Question – Optional: Alternate question to the primary question if there are multiple alternate questions, they must be given in multiple rows.
- Tags – For each question or alternate question.
- Answer – Answer to the question serves as an alternate answer when the primary question field is left blank. Answer format can be:
- Plain text
- Script with SYS_SCRIPT prefix i.e.
SYS_SCRIPT <answer in javascript format> - Channel-specific formatted response when prefixed with SYS_CHANNEL_<channel-name>, the answer can be simple or in script format:
SYS_CHANNEL_<channel-name> SYS_TEXT <answer>SYS_CHANNEL_<channel-name> SYS_SCRIPT <answer in javascript format>
- Trigger a dialog then prefix with SYS_INTENT i.e.
SYS_INTENT <dialog ref id>
- Extended Answer-1: Optional to be used in case the response is lengthy.
- Extended Answer-2: Optional to be used in case the response is lengthy.
- ReferenceId – reference to any external content used as a source for this FAQ
- Display Name – The name that would be used for presenting the FAQ to the end-users in case of ambiguity.
Nodes
This section includes settings for both nodes and tags.

- Node – Mandatory entry in the header must be blank in the following rows.
- Que ID – The Question ID is auto-generated by the platform. This field uniquely identifies the FAQs and it should not be added or edited manually. Leave this field blank if you are adding a new FAQ. Do not alter the value of this field if you are updating an existing FAQ. Do not manually add any data in this field.
- Nodepath – Path for reaching the node/tag.
- Tag – Mandatory for tag settings, leave blank for node.
- Precondition – For qualifying this node/tag.
- outputcontext – Context to be populated by this node/tag.
- Traits – for this node/tag.
Synonyms
Use this section to enter the synonyms as key-value pairs.

- Synonyms – Mandatory entry in the header, must be blank in the following rows.
- Phrase – for which the synonym needs to be entered.
- Synonyms – Comma-separated values.
Use of bot synonyms in KG term identification can be enabled using the following:
- confidenceConfigs – Mandatory entry in the header, must be blank in the following rows.
- parameter – useBotSynonyms in this case
- value – true or false
KG Params
![]()
- KG Params – mandatory entry in the header, must be blank in the following rows.
- lang – Bot language code. For example, en for English.
- stopwords – Comma-separated values.
Traits
Trait related information can be specified as follows:

- Traits – Mandatory entry in the header, must be blank in the following rows.
- lang – Bot language code. For example, en for English.
- GroupName – Trait group name.
- matchStrategy – Pattern or probability (for ML-based).
- scoreThreshold – Threshold value (between 0 and 1) when the matchStrategy above is set to ML-based.
- TraitName – The name of the trait.
- Training data – Utterances for the trait.
For Taxonomy Based KG, the following fields can be included if there are one or more faqs linked to another faq in the KG. :
- faqLinkedTo – The faqLinkedto field identifies the source FAQ to which another FAQ is linked to. The faqLinkedTo field must contain a single, valid ‘Que ID’ of the source FAQ. ‘Que Id’ should be a valid identity generated by the platform. Do not give a reference to an FAQ that is already linked to another FAQ..
- faqLinkedBy – The faqLinkedBy field contains the list of ‘Que Ids’ of the FAQs that are linked to a particular FAQ. ‘Que Id’ should be a valid identity generated by the platform.
- isSoftDeleted – The isSoftDeleted field is used to identify the FAQs that are deleted but it has one or more FAQs linked to it.
JSONファイルから
Kore.aiでは、ナレッジグラフをJSONで作成し、アップロードすることができます。その構造を理解するために、ボットからサンプルのJSONをダウンロードすることができます。以下の指示に従い、JSONを使用してナレッジグラフを構築します。
JSONサンプルのダウンロード
- 左側ペインで、会話スキル -> ナレッジグラフをクリックします。
- インポートオプションは、それぞれのナレッジグラフにあります。
- 続行する前に、ナレッジグラフを バックアップするように指示されています。バックアップのCSVまたはJSON形式を選択します。
- バックアップ後、続行をクリックします。
- 対応するダイアログボックスで、サンプルJSONをクリックします。JSONファイルがローカルコンピュータにダウンロードされます。
JSONリファレンス
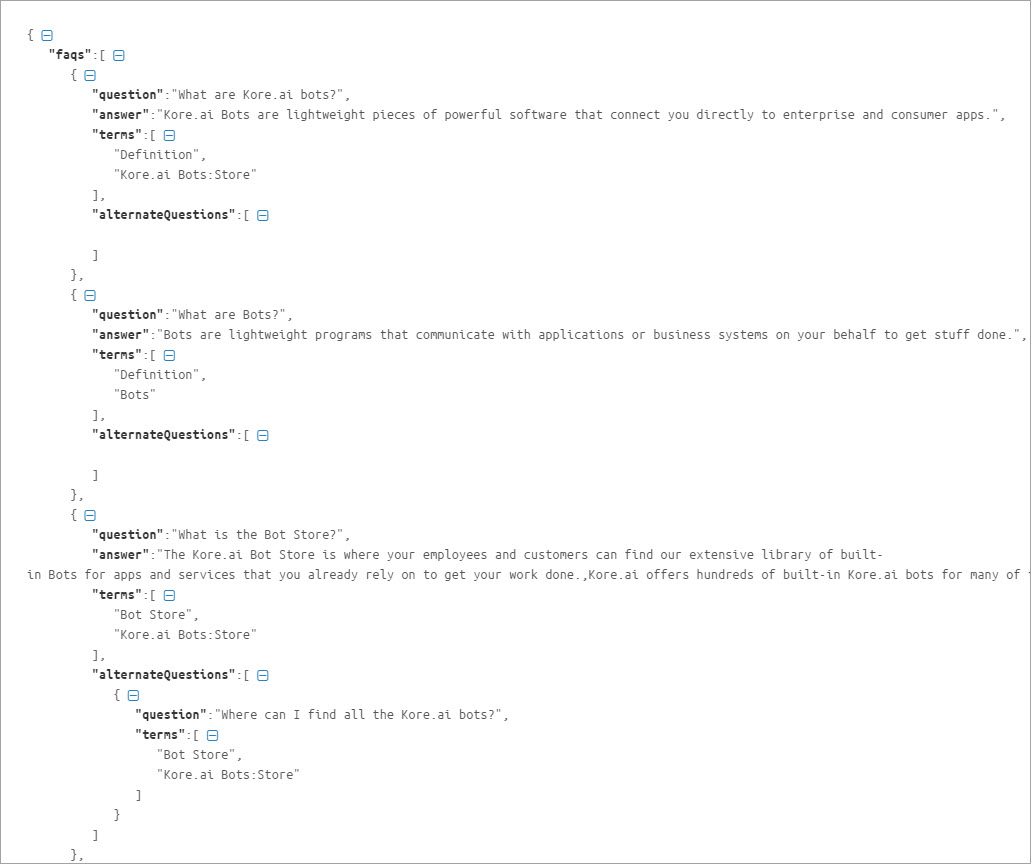
| プロパティ名 | タイプ | 説明 |
| FAQ | 配列 |
以下のもので構成されています。
|
| 質問 | 文字列 | プライマリ質問:FAQの配列に含まれる。 |
| 回答 | 文字列 | ボット対応:FAQの配列に含まれる。 |
| 用語 | 配列 | 質問が追加されたリーフノードと、第1レベルノードまでの親を含む。 |
| refId | 文字列 | このFAQのソースとして使用される外部コンテンツへの任意の参照 |
| 代替質問 | 配列 | 代替質問と用語で構成されています。リーフから第1レベルノードまでのアイテムを含む。 |
| 同義語 | オブジェクト | 用語とその同義語の配列で構成される。 |
| Unmappedpath | 配列 | 質問を持たないノードと、第1レベルノードまでのそのすべての親ノードの配列から構成される。 |
| 特性 | オブジェクト | キーとして特性の名前、値としての発話の配列から構成される。 |
タクソノミベースのKGでは、KG内の他のFAQにリンクしているFAQが1つ以上ある場合、以下のフィールドを含めることができます。:
- faqLinkedTo – ソースのFAQを識別するため。
- faqLinkedBy – リンクされたFAQを識別するため。
- isSoftDeleted – FAQは削除されたが、まだいくつかのリンクされたFAQがあることを識別するため。