Kore.aiナレッジグラフは、静的なFAQテキストを、インテリジェントでパーソナライズされた会話体験に変えるのに役立ちます。それは、FAQを平面的な質問・回答ペアの形式でキャプチャするという、通常の実践を超えています。その代わりに、ナレッジグラフでは、主要な業界用語のオントロジー構造を作成し、コンテキストに応じた質問およびその代替語、同義語、機械学習対応の示唆などと関連付けることができます。このグラフは、プラットフォームでトレーニングすると、インテリジェントなFAQ体験を実現できます。この文書は、ナレッジグラフの概念、用語、および実装について説明しています。ナレッジグラフのユースケースに基づいたアプローチについては、 こちらをご参照ください。
なぜナレッジグラフなのですか?
ユーザーは複数の方法でクエリを表現します。すべての代替質問を手動で可視化して追加するのは、困難なタスクです。Kore.aiは、ナレッジグラフをノード、タグ、同義語で設計しており、すべての一致の可能性が適用されるための作業を簡易化しています。ナレッジグラフは、ノード、タグ、および同義語を使用したトレーニングにより、さまざまな代替質問を処理することができます。ユーザーから質問があると、ナレッジグラフのノード名がチェックされ、ユーザーの発話のキーワードと照合されます。ノード名、タグ、同義語がチェックされ、そのスコアに基づいて、質問が一致する可能性の高いもの、あるいはインテントとしてショートリストに記載されます。ショートリストに載ったこれらの質問は、実際のユーザーの発話と比較され、ユーザーに提示するのに最適なインテントが導き出されます。応答には、単純な応答か、またはダイアログタスクの実行のいずれかの形式があります。このようにして、ごく少数の全く異なる代替質問をFAQに追加し、タグ、同義語、ノード名を適切に提供することで、トレーニングしていないどんな質問も一致させることができます。ナレッジグラフのパフォーマンスとインテリジェンスは、適切なノード名、タグ、同義語を使用してナレッジグラフをトレーニングする方法によって決まります。
用語解説
この文書は、ナレッジグラフの構築に使用される用語を読者に理解していただくことを目的としています。KG作成に直接ジャンプ。
用語またはノード
用語やノードは、オントロジーの構成要素であり、ビジネス業種のファンダメンタルな概念とカテゴリを定義するために使用されます。下の画像のように、「ボットオントロジー」ウィンドウの左側ペインにある用語を階層的に整理して、組織内の情報のフローを表すことができます。そこから用語の作成、整理、編集、および削除を行うことができます。最大ノード数20k、最大FAQ数50kというプラットフォームの制限があります。表現を容易にするために、いくつかの特別なノードを以下の名前で識別します。 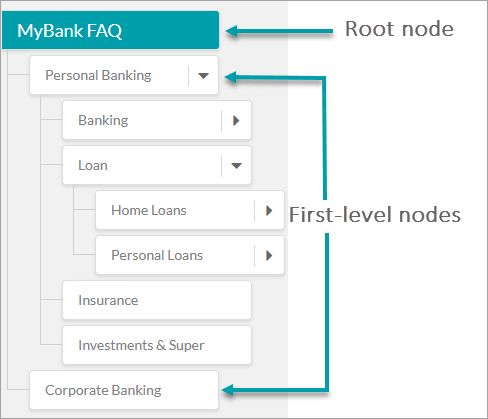
ルートノード
ルートノードは、ボットオントロジーの最上位の用語を形成します。ナレッジグラフは1つのルートノードのみで構成され、オントロジー内の他のすべてのノードはその子ノードとなります。ルートノードは、デフォルトではボットの名前を取りますが、必要に応じて変更することができます。このノードは、ノード認定や処理には使用されません。パスの認定は、第1レベルのノードから始まります。ルートノードの直下にFAQを置くことは好ましくありませんが、必要に応じて、FAQの数をルートノードで最大100に制限する必要があります。
第1レベルのノード
ルートノードのすぐ次のレベルのノードを第1レベルノードと呼びます。コレクションには、任意の数の第1レベルノードが存在します。部門名や機能名などの高レベルの用語を表すために、第1レベルのノードを残しておくことをお勧めします。例:パーソナルバンキング、オンラインバンキング、およびコーポレートバンキング。
リーフノード
質問・回答セットやダイアログタスクが追加されたノードは、どのレベルであっても リーフノードと呼ばれます。
ノード関係
オントロジー内での位置に応じて、ノードは第1レベルノード、第2レベルノードなどと呼ばれます。第1レベルノードとは、第2レベルノードと呼ばれる1つ以上のサブカテゴリをその下に持つカテゴリです。例として、ローンはホームローンとパーソナルローンの第1レベルノードです。パーソナルローンは、もう一度、2つのサブカテゴリノードを持つことができます。レートと料金、ヘルプとサポート。
タグ
同義語
ユーザーは、オントロジーの用語にさまざまな選択肢を使用します。ナレッジグラフでは、用語の同義語を追加することで、可能性のある代替形式の用語をすべて含めることができます。また、同義語を追加することで、代替質問をボットにトレーニングする必要性も軽減します。例として、インターネットバンキングのノードには、以下のような同義語が追加されます。オンラインバンキング、 eバンキング、サイバーバンキング、 Webバンキング。ナレッジグラフで用語の同義語を追加する際、ローカルまたはグローバルな同義語として追加することができます。ローカルな同義語(またはパスレベルの同義語)は、その特定のパスでのみ用語に適用されるのに対し、グローバルな同義語(またはナレッジグラフの同義語)は、オントロジー内の他のパスに出現しても用語に適用されます。リリース7.2以降では、ナレッジグラフエンジン内でボットの同義語を使用してパスの確認や質問の一意を行うことができます。この設定では、ボットの同義語とKGの同義語に同じ同義語のセットを再作成する必要はありません。
特性
メモ:v7.0以降、v6.4以前のクラスの代わりに特性が採用されています。特性とは、エンドユーザーが特定のインテントに関連する情報を求める際に、質問の性質を定義する一般的なエンドユーザー発話のコレクションです。特性については、こちらをご覧ください。特性は、ボットオントロジーの複数の用語に適用されます。
インテント
ボットは、ユーザーからの質問に対して、ダイアログタスクやFAQを実行して応答することができます。
- FAQ:質問・回答ペアは、ボットオントロジーの関連ノードに追加する必要があります。最大50kのFAQが許容されます。質問はユーザーごとに異なるため、これをサポートするには、各質問に複数の代替形式を関連付ける必要があります。代替質問の前に||をつけると、FAQのパターンを入力することができます(7.2リリース以降)。
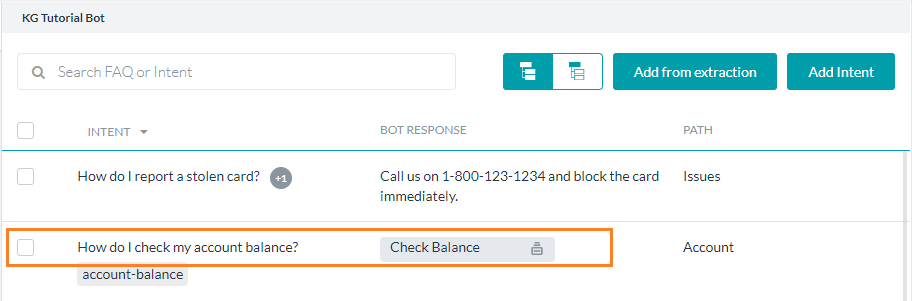
- タスク:KGインテントにダイアログタスクをリンクさせることで、ナレッジグラフとダイアログタスクの機能を活用し、複雑な会話を伴うFAQに対応することができます。
パフォーマンスの向上
ナレッジグラフエンジンは、デフォルト設定でも十分に機能します。ボット開発者は、KGエンジンのパフォーマンスをさまざまな方法で微調整することができます。
- 用語、同義語、プライマリ質問と代替質問、ユーザーの発話を定義して、ナレッジグラフを設定します。階層はKGエンジンのパフォーマンスには影響しませんが、KGエンジンの作業を組織化し、正しく導くのに役立ちます。
- 以下のパラメータの設定:
- パスの範囲 – ユーザーの発話に含まれる用語のうち、パスに含まれる最小の割合を定義することで、さらにスコアリングを高めることになります。
- KGの明確なスコア – KGインテント一致の最小スコアを定義することで、確定的な一致と見なし、他のインテントの一致が見つかっても破棄します。
- ナレッジタスクのための最小および決定的なレベル – ナレッジタスクが発生した場合に特定して対応するための最小および確定レベルのしきい値を定義します。
- KG提案数 – KGのインテントが明確に一致しない場合に提示するKG/FAQ提案の最大数を定義します。
- 提案型一致の近接性 – トップスコアとすぐ次の提案された質問の間に許容される最大の差を定義して、それらを同等に重要なものと見なします。
プラットフォームでは、上記のしきい値のデフォルト値が提供されていますが、これらは 自然言語>トレーニング>しきい値と設定からカスタマイズできます。
- コンテキストパスの限定 – これは、ボットのコンテキストが一致したインテントの用語/ノードで入力され、保持されていることを確認するものです。これにより、ユーザー体験をさらに高めることができます。
- 特性 – 前述のように、特性は、ユーザーの発話に用語/ノードが含まれていない場合でも、ノード/用語を限定するために使用されます。特性は、提案されたインテントのリストをフィルタリングするのにも役立ちます。
KGエンジンの作動
ナレッジグラフエンジンは、ユーザーの発話に対する適切な応答を抽出しながら、2段階のアプローチを使用します。これは、検索駆動型のインテント検出処理とルールに基づいたフィルタリングを組み合わせたものです。ユーザーの発話におけるパスの範囲(必要な用語の割合)と用語の使用方法(必須またはオプション)の設定は、FAQインテントの最初のフィルタリングに役立ちます。トークン化とnグラムに基づくコサインスコアリングモデルにより、最終的な検索基準を満たすことができます。ナレッジグラフのトレーニングには、以下のような手順があります。
- すべての用語/ノードおよび同義語が識別され、インデックスが作成されます。
- これらの指標を用いて、KGインテントごとにぴったり合ったパスが確立されます。
ナレッジグラフエンジンがユーザーの発話を受け取ると、次のようになります。
- ユーザーの発話とKGのノード/用語をトークン化し、nグラムを抽出します(ナレッジグラフエンジンは最大4グラムまでサポート)。
- トークンは、それぞれのインデックスを得るために、KGノード/用語とマッピングされます。
- ユーザーの発話とKGノード/用語との間のパス比較により、その発話に対して限定パスが確立されます。このステップでは、上述のパス範囲と用語の使用を考慮します。
- 限定パスの質問のリストから、コサインスコアリングに基づいて最適なものが選ばれます。