お客様のバーチャルアシスタントを構築およびトレーニングすると、Kore.aiプラットフォームは、ユーザーの発話をBotのインテントにマッピングするMLモデルを構築します(詳細はこちらをクリック)。作成したら、MLモデルの不偏の一般化能力を把握および推定できるようモデルを検証しておくと良いでしょう。
Kore.aiのバーチャルアシスタントプラットフォームでは、以下の2つの検証方法をご利用いただけます。
- 混同行列またはエラーマトリックスを使用して、機械学習モデルのパフォーマンスを可視化します。
- K-分割交差検証で機械学習モデルのスキルを推定します。
トレーニング > 機械学習の発話から、モデルを検証ドロップダウンリストを使用して検証方法を選択することで、検証モデルを選択することができます。対応する検証方法の結果ページに移動します。

以下のセクションでは、それぞれの方法について詳しく説明します。
K-分割交差検証
(プラットフォームのバージョン8.0で導入)
交差検証は、限られたデータサンプル上で機械学習モデルを評価するために使用される再サンプリング手順です。この手法は、データを部分集合に分割し、ある部分集合でデータをトレーニングし、その他の部分集合をモデルのパフォーマンス評価に使用することを含みます。交差検証を実行することで、モデルのパフォーマンスに関するより一般的な指標が得られます。これはMLモデルのパフォーマンスのより優れた指標です。
設定
Kore.aiのバーチャルアシスタントプラットフォームは、K-分割交差検証をサポートしています。このため、お客様はNLPの詳細設定からK-分割パラメータを交差検証用に設定する必要があります。詳細はこちらをクリックしてください。
トレーニングを開始し、K-分割検証レポートを生成するには、以下の手順に従います。
- Botサマリーページの左側のペインで、自然言語 > トレーニングをクリックします。
- トレーニングページで、右上のモデルの検証ドロップダウンリストをクリックし、K-分割交差検証を選択します。
- K-分割交差検証ページで、生成をクリックしてトレーニングを開始し、K-分割検証レポートを生成します。生成ボタンは、初めて交差検証を実行したときにのみ表示されます。
- レポート生成後は、右上の再生成ボタンをクリックすると、必要に応じてレポートを再度生成することができます。
注:検証は、トレーニングに使用されたML発話の総数が250以上の場合にのみ実行されます。この数はオンプレミスのインストールで設定可能です。詳細はサポートチームにお問い合わせください。
実装
以下は、K-分割交差検証の実行中にプラットフォームが従う手順です。
- 一連の発話はすべて、トレーニングデータセットとテストデータセットにランダムに分割されます。
- トレーニングデータ全体が「K」分割に分割され、それぞれのサブセットには同数のトレーニングする発話が含まれます。「K」分割の値は、上述のように設定を行う必要があります。
- その後システムは「K」反復を実行し、それぞれの反復では、発話のサブセット(分割)が残りのサブセット(「K-1」分割)を使用してトレーニングされたモデルに対してテストされます。
- 結果として得られたモデルは、パフォーマンス測度を計算するためにテストデータセット上で検証されます。
- このプロセスは、すべての発話がモデルのテストに少なくとも1回は使用されるまで繰り返されます。
- メトリクスは、MLモデルのパフォーマンスを評価する際に役立つよう、K-分割交差検証後に提供されます。
結果の把握
以下のメトリクスは、K分割交差検証後に提供されます。

- それぞれのテスト分割の精度スコア – モデルの精度/正確さを定義するためのもので、予測された陽性の合計(真陽性と偽陽性の合計)に対する真陽性の比率として計算されます。
- それぞれのテスト分割のリコールスコア – 正常に識別された関連する発話の割合を定義するためのもので、実際の陽性(真陽性と偽陰性の合計)に対する真陽性の割合として計算されます。
- それぞれのテスト分割のF1スコア – クラス分布を均等にし、精度とリコールのバランスを求めるためのもので、精度とリコールの加重平均として計算されます。
- すべての分割の精度、リコール、F1スコアの平均。
関連するメトリクスの理解を深めるために、以下の情報も提供しています。
- 発話の合計 – トレーニングコーパスに含まれる発話の数
- インテント数 – Bot内のインテントの総数
- 分割の数 – トレーニングコーパスが分割されたサブセットの数、K-分割パラメータ
- 分割あたりのテストデータ – テストに使用される各サブセットの発話数
- 分割あたりのトレーニングデータ – トレーニングに使用される各サブセットの発話数
注:これらの結果は、より正確で、少なくとも250の発話を含む大規模な発話データセットで実行した場合のMLモデルのパフォーマンスの代表的なものです。
K-分割交差検証レポートのエクスポート
(プラットフォームのバージョン8.1で導入)
K-分割交差検証レポートを生成したら、レポートをCSV形式でエクスポートすることができます。検証レポートをエクスポートするには、以下の手順に従ってください。
- K-分割交差検証ページで、右上のエクスポートアイコンをクリックします。
- レポートのエクスポートダイアログ ボックスで、続行をクリックします。
エクスポートされたファイルは以下の形式で表示されます。 Kfold_BotName_YYYYMMDDHHmmSS.csv.
混同行列
(以前のMLモデルを指す)
混同行列は、真の値が既知のテストデータのセット上における分類モデル(または「分類子」)のパフォーマンスを記述するのに便利です。混同行列によって生成されたグラフは、Botタスクに対するトレーニング済みの発話のパフォーマンスを一目で確認することができます。混同行列という名前は、モデルが発話を混同させているかどうかを簡単に確認できるという事実に由来しています。
MLモデルグラフは、それぞれのBotタスクに対してすべてのトレーニング発話を評価し、それらを真陽性(True +ve)、真陰性(True -ve)、偽陽性(False +ve)、偽陰性(False -ve)のいずれかにプロットします。グラフを見ると、どの発話とインテントの一致が正確で、良い結果を生み出すためにさらにトレーニングすべきかがわかります。
真の象限での発話が高い位置にあるほど、期待される動作を示します – True +veはトレーニング対象のタスクとの強い一致を表し、True -veは予想どおり無関係なインテントとの不一致を表します。真象限のある程度の発話は、より良いスコアを得るためにさらにトレーニングすることができます。
偽象限に分類される発話には注意が必要です。これらは、意図したタスクと一致していない、あるいは間違ったタスクと一致している発話です。任意の象限の発話テキストを読むには、グラフのドットにカーソルを合わせてください。

真陽性の象限
インテントに対してトレーニングされた発話が、そのインテントに対して陽性の信頼度スコアを受け取った場合、その真陽性の象限に分類されます。この象限は、好ましい結果を表しています。しかし、象限の尺度上の発話が高い位置にあるほど、正しいインテントを見つけられる可能性が高くなります。
注:複数のBotタスクの真陽性の象限に該当する発話は、修正が必要なBotタスクが重複していることを表しています。
真陰性の象限
インテントに対してトレーニングされていない発話が、そのインテントに対して陰性の信頼度スコアを受け取った場合、真陰性の象限に分類されます。この象限は、その発話がインテントと一致することが想定されていないため、好ましい結果を表しています。この象限の尺度上の発話が低い位置にあるほど、発話がインテントから離れている可能性が高くなります。特定のBotタスクのためにトレーニングされたすべての発話は、理想的には他のタスクの真陰性の象限に分類されるべきです。
偽陽性の象限
インテントに対してトレーニングされていない発話が、そのインテントに対して陽性の信頼度スコアを受け取った場合、その発話は偽陽性の象限に分類されます。この象限は、好ましくない結果を表しています。このような結果の場合、最適な結果を得るためには、発話、意図されたBotタスク、および一致が不正確なタスクをトレーニングする必要があります。
偽陰性の象限
インテントに対してトレーニングされた発話が、そのインテントに対して陰性の信頼度スコアを受け取った場合、偽陰性の象限に分類されます。発話がインテントと一致すると想定されるため、この象限は好ましくない結果を表しています。このような結果の場合、最適な結果を得られるよう発話、意図されたBotタスク、タスクをトレーニングする必要があります。詳細については機械学習を参照してください。
注:MLモデルグラフに反映させるために、Botに変更を加えた後は、必ず[トレーニング]ボタンをクリックしてください。
グラフを参照する際には、以下の重要なポイントを考慮してください。
- 真の象限の高い位置にある発話は、期待される動作をよく示します。
- 真の象限の中間に位置する発話は、より良いスコアを得るためにさらにトレーニングする必要があります。
- 偽の象限の低い位置にある発話には、注意する必要があります。
- 複数のBotタスクの真の象限に該当する発話は、修正が必要なBotタスクが重複していることを示しています。
良い/悪いMLモデルについての理解
MLモードの良し悪しを理解するための一例として、ある銀行のBotをもとに考えてみましょう。このBotには、300以上のトレーニング済みの発話を含む、複数のタスクがあります。下の画像は、4つのタスクとそれに関連した発話を示しています。
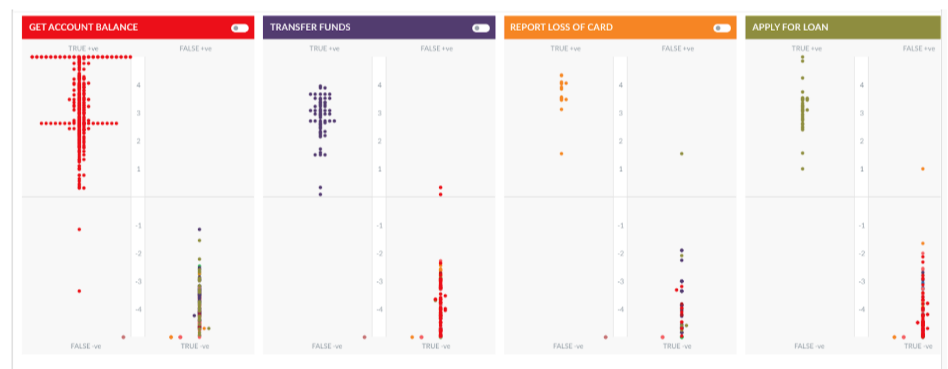
このシナリオのモデルはかなりよくトレーニングされており、タスクに関連する発話のほとんどが真陽性の象限に集中しており、他のタスクの発話のほとんどは真陰性の象限にあります。

開発者は、このモデルの以下の点を改善することに努めます。
- 「Get Account Balance」というタスクのMLモデルでは、偽陽性の象限にいくつかの発話(B)が見られます。
- 「Get Account Balance」用にトレーニングされた発話は、真陰性の象限(C)に表示されます。
- モデルは十分にトレーニングされており、このタスクの発話のほとんどは真陽性の象限の上部に位置していますが、一部の発話のスコアは依然として非常に低いままです。(A)
- ドットの上にカーソルを置くと、発話が表示されます。A、B、Cの場合、発話はインテントと完全に一致しているはずにもかかわらず、類似する発話が別のインテント用にトレーニングされているため、スコアが低い、あるいはマイナスになっています。
注:このような場合には、テスト > トレーニングモジュールを用いて、MLエンジンが返すインテントとそれに関連するサンプル発話を確認することをお勧めします。発話を調整してからもう一度お試しください。
- Report Loss of Cardというタスクには、集結した限定的な発言が含まれています。
以下のトラベルBotのMLモデルと比較してみましょう。
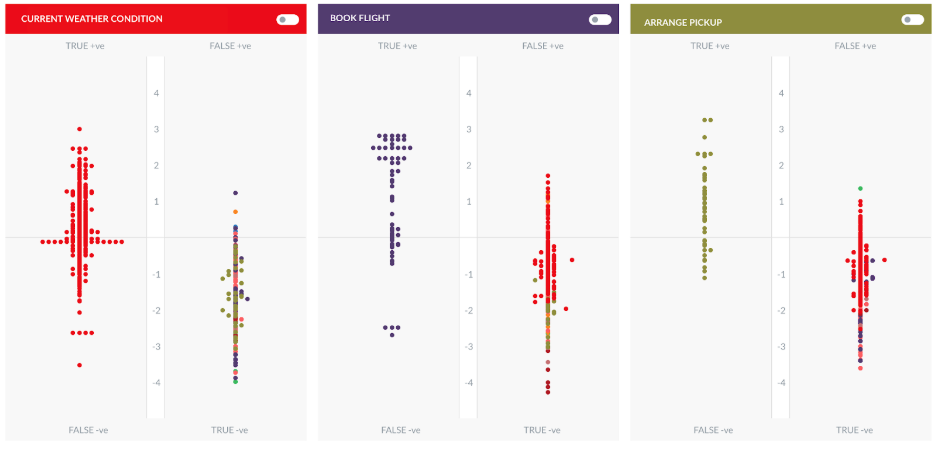
モデルは多くの矛盾する発話とともにトレーニングされているため、結果として発話が分散しています。これは悪いモデルとみなされ、Bot内の複数のタスクに関連していない、より小さな発話のセットで再度トレーニングする必要があります。
特定のタスクの発話のグラフ表示
MLモデルグラフには、すべてのBotタスクに対してトレーニングされたすべての発話のパフォーマンスがデフォルトで表示されます。他のすべてのインテントに対する特定のBotタスクのトレーニングされた発話のパフォーマンスを表示するには、下の画像のように、そのBotタスクのスイッチを切り替える必要があります。

注:これらは最初のBotタスクのトレーニングされた発話であるため、発話はそのタスクのTrue +ve象限の上部に、他のすべてのタスクのTrue -ve象限の下部に表示されるのが理想的です。
MLモデルグラフのフィルタリング
MLモデルグラフを以下の条件でフィルタリングすることができます。

- 開発中または公開済み:デフォルトでは、開発中と公開済みのすべてのタスクのグラフが表示されます。スイッチを切り替えると、公開済みタスクのみのグラフが表示されます。
- 弱から強:タスクのスコアが最も正確でないものから最も正確なものまでのグラフを表示します。
- 強から弱:タスクのスコアが最も正確なものから最も正確でないものまでのグラフを表示します。
- タスク/インテント:すべてを選択するか、特定のタスク名を選択してグラフを表示します。
- 発話:すべてを選択するか、または特定のトレーニング済みの発話を選択してグラフを表示します。
発話の編集と再マッピング
MLグラフから直接ユーザーの発話を編集したり、他のタスクに割り当てたりしてスコアを向上させることができます。これを行うには、象限をクリックすると象限ビューが開き、タスク名とそれに関連するすべての発話が表示されます。

個々の発話を編集するには、発話の編集アイコンをクリックします。発話の編集ウィンドウが開きます。予想されるタスクドロップダウン リストを使用して、発話フィールドのテキストを変更したり、他のタスクに発話を再度割り当てたりすることができます。
