NLP models play a significant role in providing natural conversational experiences for your customers and employees. Improving the accuracy of the NLP models is a continuous journey and requires fine-tuning, as you add new use cases to your virtual assistant. The Kore.ai XO Platform proactively validates the NLP training provided to the virtual assistants and provides recommendations to improve the model. This article explains the available validations, how to view these validations, and how to validate the NLU Model.
Goal-Driven Training Validations
The ML engine enables you to identify issues proactively in the training phase itself with the following set of recommendations:
- Untrained Intents – notifies about intents that are not trained with any utterances so that you can add the required training.
- Inadequate training utterances – notifies the intents with insufficient training utterances so that you can add more utterances to them.
- Utterance does not qualify any intent (false negative) – notifies about an utterance for which the NLP model cannot predict any intent. For example, an utterance added to Intent A is expected to predict Intent A. Whereas in some cases the model won’t be able to predict neither the trained Intent A nor any other Intents within the model. Proactively identifying such cases helps you rectify the utterance and enhance the model for prediction.
- Utterance predicts wrong intent (false positive) – Identifies utterances that predict intents other than the trained intent. For example, when you add an utterance similar to utterances from another intent, the model could predict a different intent rather than the intent it is trained to. Knowing this would help you to rectify the utterance and improve the model prediction.
- Utterance predicts intent with low confidence – notifies about the utterances that have low confidence scores. With this recommendation, you can identify and fix such utterances to improve the confidence score during the virtual assistant creation phase.
- Incorrect Patterns– Notifies about the patterns that do not follow the right syntax along with the error. You can resolve such incorrect patterns to improve intent identification. In addition, the Platform now supports the following Non-CS languages for Virtual Assistant conversations:
- Polish: Support for stop words and entity detection improvements for Number, City, Country, Person, Date, Time, Zip Code, Address, and LoV Enumerated.
- Japanese: Support for stop words and improvements in entity detection, intent patterns, sub-intents, and bot synonyms.
- Arabic: Support for stop words and improvements in phone number entity detection.
- Hinglish (Hindi + English): The support for this dual language combination is newly introduced.
- Wrong Entity Annotations – notifies wrongly annotated entities. For example, in the utterance ‘I want to travel to Hyderabad on Sunday 2pm’,. the Travel Date (Date type) entity is annotated with value ‘2PM’ (Time value). The platform checks for such wrong annotations and notifies the issue against the utterance, which helps to re-annotate the entity with the right values and improve entity recognition.
- Short Utterance – notifies about the utterances whose word count is lesser than or equal to two. It helps you to follow best practices for the length of utterances, which depicts an actual end-user query and further improves the model’s accuracy.
How to View NLU Training Validations
- On the virtual assistant’s Build menu, click Natural Language -> Training.
- In the Intents tab, you can see the set of recommendations for the Intents and ML utterances.

Note: The errors and warnings in this screen are examples. The ML validations vary based on the error or waning recommendation as explained in the Goal-Based NLU Training Validations section above. - Hover over the validation options and view the following recommendations:
- Hover on the
 Error icon to view the recommendations to resolve the error.
Error icon to view the recommendations to resolve the error. 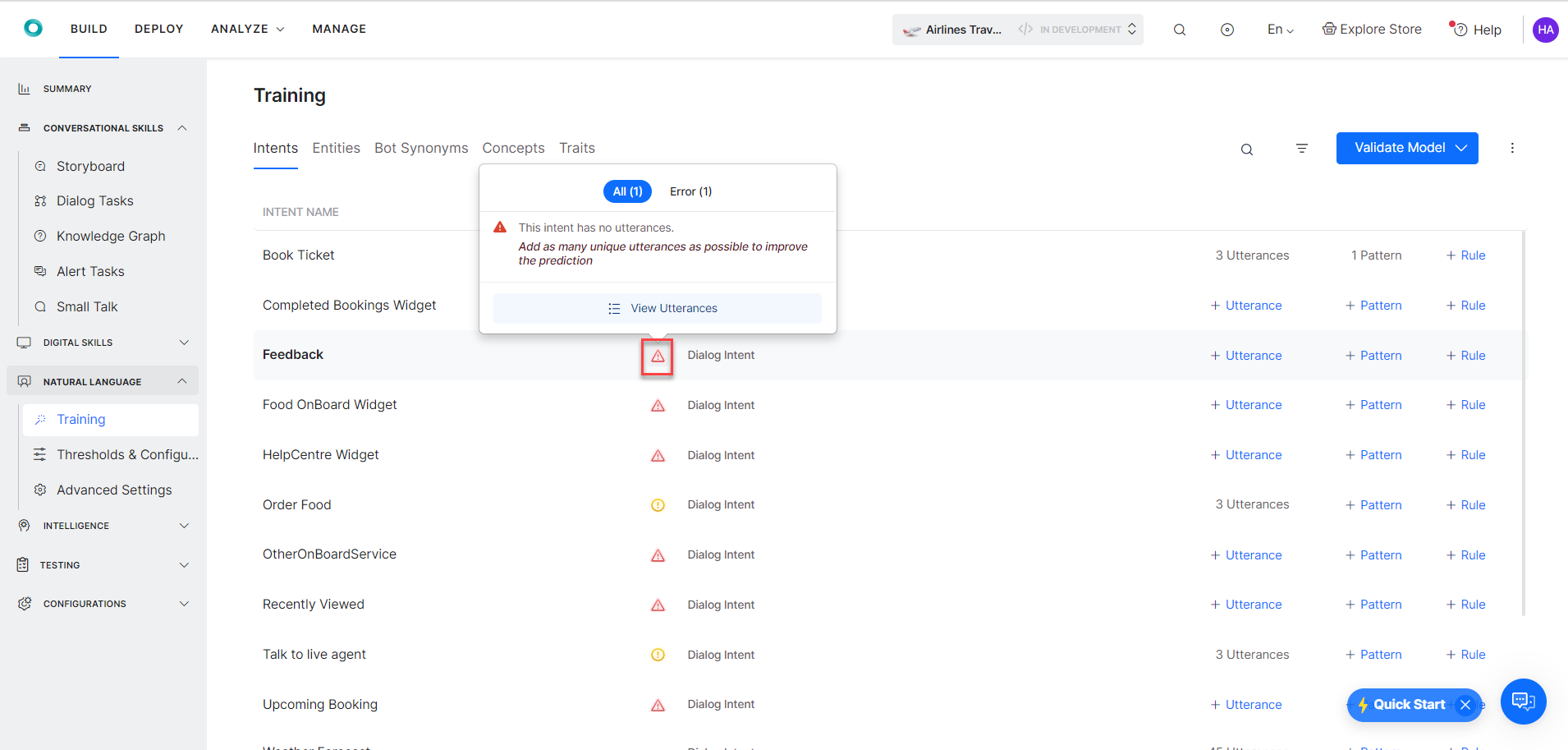
Note: An Error is displayed when the intent has a definite problem that impacts the virtual assistant’s accuracy or intent score. Errors are high severity problems.
- Hover on the
- Hover on the
 Warning icon and follow the instructions in the warning to enhance the training for ML utterances.
Warning icon and follow the instructions in the warning to enhance the training for ML utterances.
- Once you click on the Intent with error or warning, hover over the
 Bulb icon to view the summary of error or warning messages as illustrated below:
Bulb icon to view the summary of error or warning messages as illustrated below: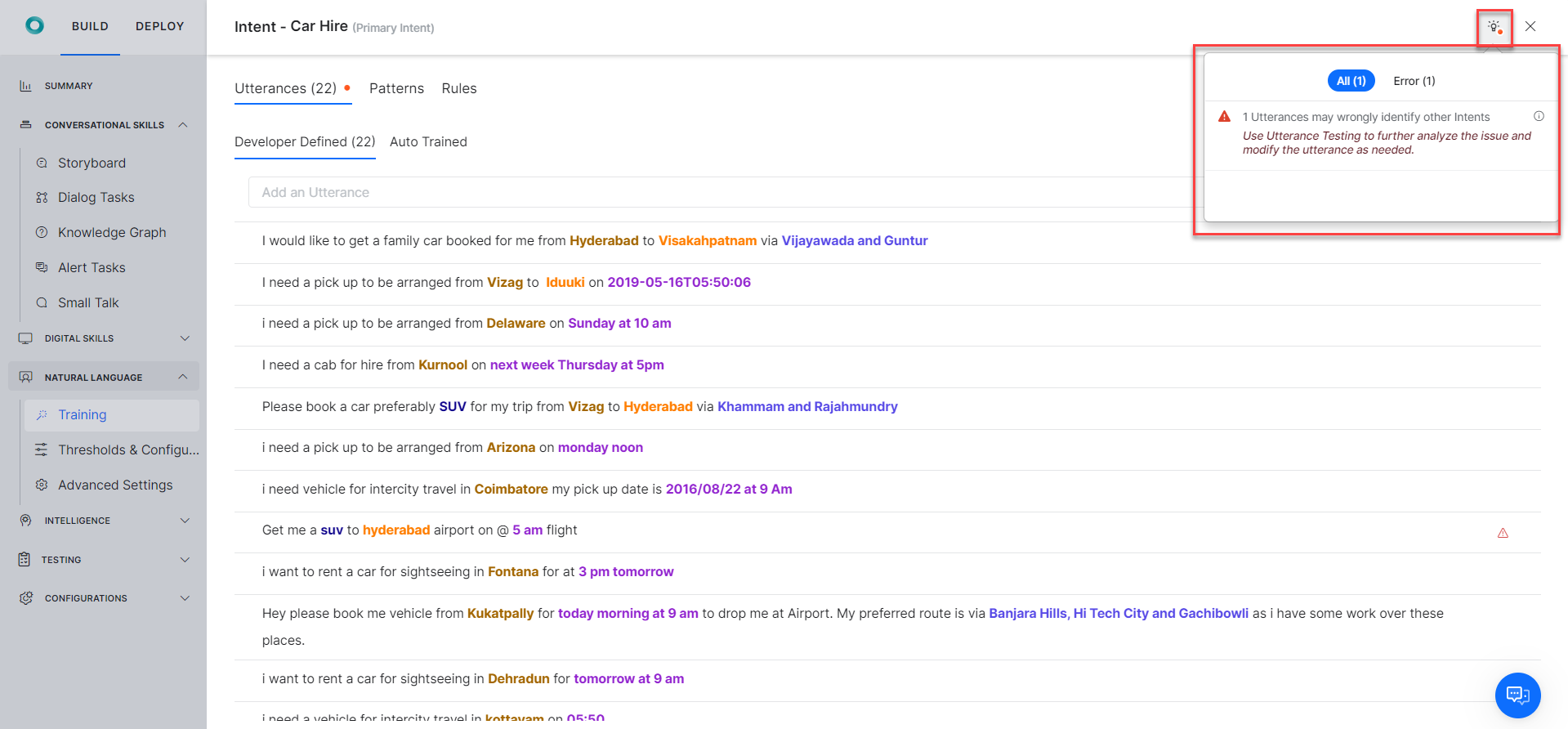
Note: A warning is displayed when the issue impact the VA’s accuracy and it can be resolved. Warnings are less severe problems when compared to errors.
How to Use the NLU Validate Model
The NLU Validate Model provides the options to view the training module’s recommendations summary, refresh the recommendations, and view the Confusions Matrix, and K-fold Cross Validation reports.
The Validate Model helps you follow the best practices and quickly attain NLP accuracy for your Virtual Assistants.
Recommendations Summary
The Recommendations Summary is available when validating your model. This feature gives insights into the problem areas, errors, warnings for the intents that are building blocks for your virtual assistant’s training, and recommendations on corrective actions for better NLU accuracy.
To view the Recommendations Summary, follow the steps below:
- Navigate to Build > Natural Language and click the Training option on the left menu.
- On the Training page, click the Validate Model button.
- The recommendations summary slider appears with the list of issues and the recommended actions to fix them.
 Note: All the recommendations are listed under the All tab. Under the Error and Warning tabs, you can view recommendations specific to errors and warnings specifically.
Note: All the recommendations are listed under the All tab. Under the Error and Warning tabs, you can view recommendations specific to errors and warnings specifically.

Understanding the Recommendations
In the recommendation message, 5 intents have Patterns with invalid syntax, 5 is the count of the intents with the issue – patterns with invalid syntax. The intent count is displayed first for any recommendation, followed by the issue type. When you fix an issue based on the recommendation, the training model updates, and the platform automatically triggers a background task to refresh the recommendations summary.
Filter the Recommendations
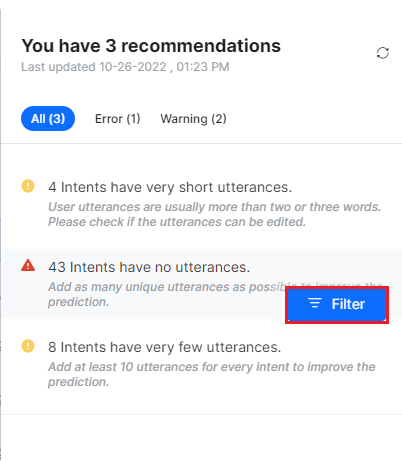
Previously, for example, when an issue titled “5 Intents have utterances with low confidence score” was displayed, there was to identify the intents immediately. The user had to move the cursor against each intent in the list to identify the ones causing training issues.
The Platform now provides a Filter option in the training module to quickly identify intents and training data with issues and fix them. When applied to the recommendations list, the filter groups all the related issues and displays them in the Training panel to give you a focused view of all the open training issues.
To filter the recommendations summary issue, follow the steps below:
- Hover over the desired issue on the recommendations summary slider and click the Filter button.
- In the Training panel, all the intents with the issue type are listed. For example, if the user selects ‘43 Intents have no utterances‘, the platform filters out those 43 intents from the list of all intents. A note on the filter applied displays on the panel, and an option to reset the applied filter is available as shown below:
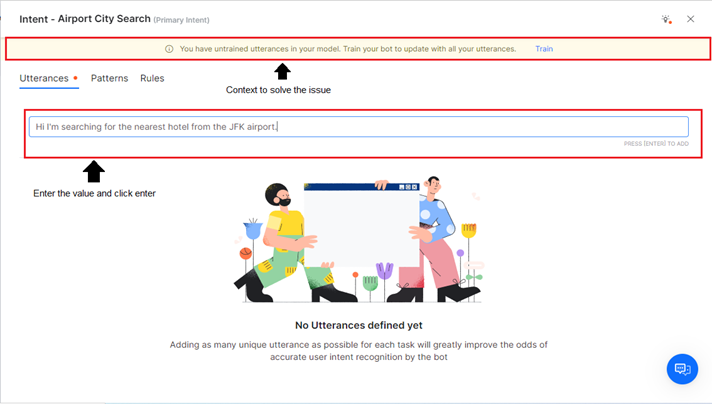
- Click the +Utterance, +Pattern, or +Rule link for an intent issue type to add the relevant values for training.
- Enter the values in the relevant textbox and click enter under the Intent summary window’s Utterance/Pattern/Rule tab. The Intent Summary window displays the context to resolve the filtered issue.
- The utterance/pattern/rule is created successfully and mapped to the intent.
- Once you resolve an intent type issue, the system updates (decrements) the issues’ count and the error indicator (red dot) on the Recommendation Summary panel.
- Similarly, the system updates the Error and Warning counts if an error or warning is resolved.



Important
- The user can filter only one recommendation at a time.
- When a filter is selected, it applies to the Intent training, utterance, rule, and pattern-level recommendations for the selected intent type.
Reset the Intent Recommendation Filter
With the CLEAR FILTER option, you can clear or reset a filter selection for an intent type issue. Once the filter is reset, an unfiltered view of all the intent names and intent types (errors and warnings) with all the training data (Utterances, Patterns, Negative Patterns, etc.) is displayed.
To reset the intents recommendation filter, follow the steps below:
- Click the CLEAR FILTER link under the Training > Intents tab.
- All the intent type entries are displayed without filtering the data.

Refreshing Recommendations
In the recommendation summary, you can refresh recommendations as explained in the previous section in some of the scenarios like:
When you click the Refresh icon, a timestamp of the last refresh is displayed along with the refreshed recommendations list. The timestamp is updated with every refresh.
 “
“If there are untrained utterances in the training model, the platform provides you with the following options:
Train and Regenerate
This option allows you to train the model with untrained utterances, and then triggers a background task to generate recommendations from the latest model.
The following steps explain the Train & Generate usage with an example.
- Click any intent and add a new utterance.
- Once the utterance is added, go to the main page and click the Refresh icon to refresh the recommendations. The following pop-up is displayed when there are untrained utterances.
- Click the Train & Regenerate button to train the utterances and regenerate the recommendations.
- A message about training initiation is displayed.
- Once training and regeneration of recommendations is completed, the status is displayed in the status docker.
- When you click the Refresh icon, the recommendations summary is refreshed and the count of recommendations is either increased, or decreased, or the recommendations are updated based on the latest results.



Regenerate
Click the Regenerate button in the displayed pop-up if you want to trigger a background task that generates recommendations from the current model.
If you click the Refresh icon when the model is being trained, recommendations from the latest Validate model are generated only once the training is completed.
For example, if new utterances are added to the intent, a new recommendation may get added to the summary list. Similarly, if a recommendation is implemented, the count of recommendations decreases. In a recommendation like 13 intents have very short utterances, if 2 intents are fixed, then the recommendation is updated to 11 intents have very short utterances.

NLU Validation Options
Next to the Validate Model, there is a drop-down with options to select either the Confusion matrix or K-fold Cross Validations.

You can also click the Go button to access Confusion Matrix and K-fold Cross Validation reports.

Confusion Matrix
Confusion Matrix is useful in describing the performance of a classification model (or classifier) on a set of test data for which the true values are known. The graph generated by the confusion matrix presents an at-a-glance view of the performance of your trained utterances against the virtual assistant’s tasks. To learn more, see the Confusion Matrix section in Model Validation.
The following screenshot shows the confusion matrix report.

K-Fold Cross Validation
K-Fold Cross-Validation is a resampling procedure used to evaluate machine learning models on a limited data sample. The technique involves partitioning the data into subsets, training the data on a subset, and using the other subsets to evaluate the model’s performance. To learn more, see the K-Fold Cross Validation section in Model Validation.
The following screenshot shows the K-Fold Cross-Validation report.
