Kore.ai NLP 엔진은 기계 학습, 기초 의미 및 지식 그래프(있는 경우) 모델을 사용하여 의도를 일치시킵니다. 세 가지 Kore.ai 엔진 모두 최종적으로 결과를 Kore.ai 순위 및 결정 구성 요소에 정확한 일치 또는 가능한 일치로 전송합니다. 순위 및 해결은 전체 NLP 계산을 통해 최종 승자를 결정합니다.
작동 방식
NLP 엔진은 기계 학습, 기초 의미 및 지식 그래프(봇에 있는 경우) 모델을 통한 하이브리드 접근 방식으로 관련성에 대한 일치 의도의 점수를 매깁니다. 모델은 사용자 발화를 가능한 일치 또는 확실한 일치로 분류합니다. 확실한 일치는 높은 신뢰도 점수를 얻은, 사용자 발화와 완벽하게 일치하는 것으로 간주합니다. 게시된 봇에서 사용자 입력이 단일한 확실한 일치와 일치하면 봇이 작업을 직접 실행합니다. 발화가 여러 개의 확실한 일치와 일치하는 경우, 최종 사용자가 하나를 선택할 수 있는 옵션으로 전송합니다. 반면에, 가능한 일치는 사용자 입력에 대해 꽤 좋은 점수를 받지만 정확한 일치라고 부를 만큼 확실하다는 생각이 들지 않는 의도입니다. 내부적으로 시스템은 점수에 따라 가능한 일치를 좋은 일치와 확실하지 않은 일치로 추가 분류합니다. 게시된 봇에서 최종 사용자의 발화가 가능한 일치를 생성한 경우, 봇은 이러한 일치를 이런 뜻이 맞습니까?라고 보냅니다. 최종 사용자를 위한 제안. 순위 및 해결에 따라 엔진 간의 최적 의도를 파악합니다. 플랫폼이 모호한 점을 발견하면 모호함 대화가 시작됩니다. 플랫폼은 사용자 발화에 대한 하나의 최상의 의도를 확인할 수 없을 때 다음 두 시스템 대화 중 하나를 시작합니다.
- 모호성 해소 대화: 엔진에서 둘 이상의 확실한 일치가 반환될 때 시작됩니다. 이 시나리오에서, 봇은 사용자에게 실행할 확실한 일치 항목을 선택하도록 요청합니다. NLP 표준 응답에서 사용자에게 표시되는 메시지를 사용자 정의할 수 있습니다.
- 대화를 의미한 것입니까: 순위 및 해결이 둘 이상의 최종 결과를 반환하거나 유일한 최상의 의도가 KG 엔진 점수가 하한 임곗값과 상한 임곗값 사이에 있는 FAQ인 경우 시작됩니다. 이 대화를 통해 사용자는 봇이 완전히 확실하지는 않은 의도와 일치하는 항목을 찾았고 사용자가 계속하기를 선택하기를 원한다는 사실을 알 수 있습니다. 이 시나리오에서, 개발자는 이러한 발화를 식별하고 봇을 추가로 학습시켜야 합니다. NLP 표준 응답에서 사용자에게 표시되는 메시지를 사용자 정의할 수 있습니다.
임곗값 및 설정
순위 및 해결 엔진을 설정하려면, 다음 단계를 따르세요.
- 임곗값을 설정하고 싶은 봇을 엽니다.
- 상단 메뉴에서 빌드 탭을 선택합니다.
- 왼쪽 탐색 메뉴에서 자연어 > 임곗값 및 설정을 클릭합니다.
- 순위 및 해결 엔진 섹션에서는 임곗값을 설정할 수 있습니다.
- 선호하는 확실한 일치는 가능한 일치보다 확실한 일치의 우선 순위를 지정하는 데 사용할 수 있으므로, 재채점을 위해 모든 일치를 염두에 두고 모호한 경우 최종 사용자가 올바른 의도를 선택할 수 있습니다. 이 설정은 기본적으로 활성화되어 있으며 비활성화할 수 있습니다. 활성화된 경우(기본 동작), 확실한 일치가 선택되고 가능한 일치는 삭제됩니다. 최종 일치가 없는 경우 가능한 일치를 재채점합니다. 비활성화된 경우 모든 일치(확실한 및 가능한)를 재채점합니다.
- 다른 의도 엔진에서 조건에 맞는 모든 의도가 최상의 의도로 간주되고 최종 사용자에게 전송하여 필요한 의도를 선택할 수 있도록, 의도 재채점하기를 끌 수 있습니다. 하나의 의도만 조건에 맞는 경우 최종 결과로 간주되고, 둘 이상의 의도가 조건에 맞으면 사용자에게 모호성 해소를 위한 결과가 나타납니다.
- 최고 스코어링 및 그와 동등하게 중요하다고 여겨지는 바로 그 다음의 가능한 의도 사이에 허용되는 최대 차이를 정의하는 가능한 일치의 근접함. 플랫폼 v7.3 이전에는, 이 설정이 기초 의미 섹션에 있었습니다.
- 종속성 파싱 모델은 기초 의미 모델로 의도 인식이 가능할 뿐만 아니라 순위 및 해결 엔진으로 의도의 재채점도 활성화할 수 있습니다. 이 설정은 기본적으로 비활성화되어 있으며 무조건 설정해야 합니다. 자세한 내용은 아래를 참조하세요.

종속성 파싱 모델
플랫폼에는 Fundamental Meaning Engine, 순위 및 해석 엔진을 통한 의도 채점 모델 두 개가 있습니다.
- 첫 번째 모델은 주로 단어의 존재, 발화에서 단어의 위치 등에 의존하여 의도를 결정하며 Fundamental Meaning Engine으로만 점수를 매깁니다. 이는 기본 설정입니다.
- 두 번째 모델은 의도 탐지가 단어, 단어의 상대적 위치 및 가장 중요하게는 문장의 키워드 간 종속성을 기반으로 하는 종속성 매트릭스를 기반으로 합니다. 이 모델에서 Fundamental Meaning Engine으로 의도의 점수를 매긴 다음 순위 및 해석 엔진에서 다시 점수를 매깁니다.
종속성 파싱 모델은 학습 > 임곗값 & 설정의 순위 및 해결 섹션에서 활성화하고 설정할 수 있습니다. 참고: 이 기능은 선택 언어에 대해서만 지원됩니다. 지원되는 언어는 여기를 참조하세요. 종속성 파싱 모델은 다음과 같이 설정할 수 있습니다.
- 최소 일치 점수는 의도를 가능한 일치로 규정하기 위한 최소 점수를 정의합니다. 0.0에서 1.0 사이의 값으로 설정할 수 있으며 기본값은 0.5로 설정되어 있습니다.
- 고급 설정은 다양한 매개 변수와 관련된 가중치 및 점수를 변경하여 모델을 사용자 정의하는 데 사용됩니다. 그러면 유효한 코드를 입력할 수 있는 JSON 편집기가 열립니다. 기본 설정으로 복원을 클릭하여 JSON 구조의 기본 임곘값 설정을 가져올 수 있습니다. 결과를 알고 있는 경우 설정을 변경할 수 있습니다.

NLP 탐지
자연어 분석의 결과는 다음과 같은 시나리오입니다.
- FM 또는 ML 또는 KG 엔진과의 확실한 일치를 식별하는 NLP 분석.
- 여러 엔진이 가능한 일치를 반환하고 단일 일치를 선택하는 NLP 분석.
- 여러 엔진이 가능한 일치를 반환하고 해결이 여러 결과를 반환하는 NLP 분석.
- 일치 항목이 없는 NLP 분석.
위의 각 경우에 대해 이 섹션에서 설명합니다. NLP 탐지를 이해하기 위해, 다음 세부 정보가 포함된 뱅킹 봇의 예를 사용하겠습니다.
- 봇은 5개의 대화 작업 및 기본 대화로 구성됩니다.
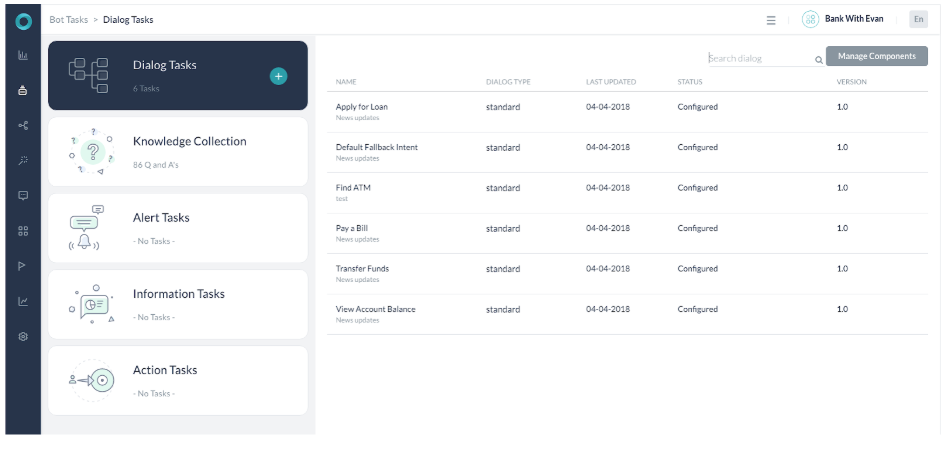
- 의도는 동의어, 패턴 및 ML 발화로 학습시킵니다.
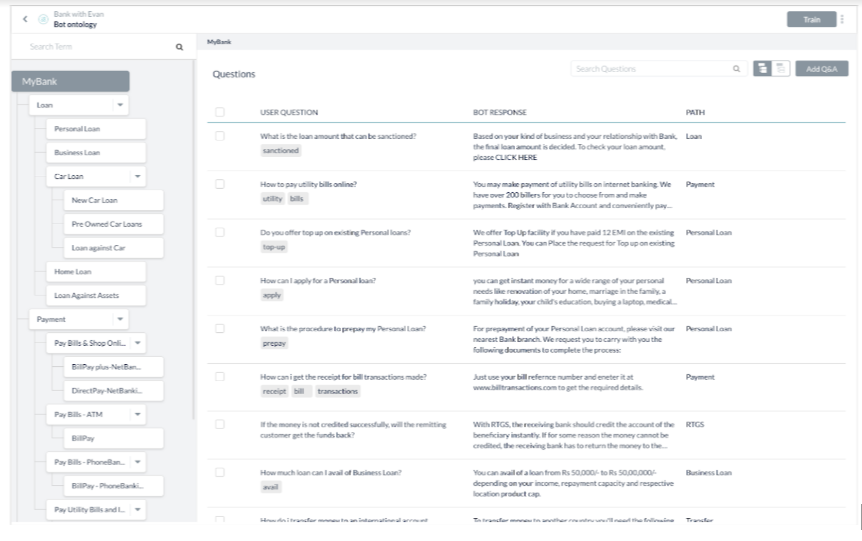
- 봇은 4개의 최상위 용어로 분산된 86개의 FAQ로 정의된 지식 그래프로 구성됩니다.
시나리오 1 – 확실한 일치를 식별하는 FM
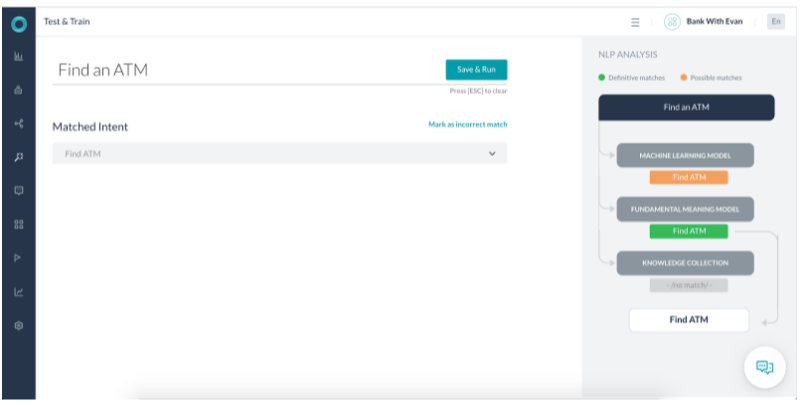
- Fundamental Meaning(FM) 모델이 발화를 확실한 일치로 식별했던 경우입니다.
- Machine Learning(ML) 모델도 이를 가능한 일치로 식별했습니다.
- 식별된 작업의 반환된 점수는 다른 의도 점수보다 6배 높습니다. 또한, 의도 이름의 모든 단어는 사용자 발화에 있습니다. 따라서 FM 모델은 이를 확실한 일치로 명명했습니다.
- ML 모델은 ATM 찾기 의도를 가능한 일치로 일치시킵니다.
시나리오 2 – 확실한 일치를 식별하는 ML
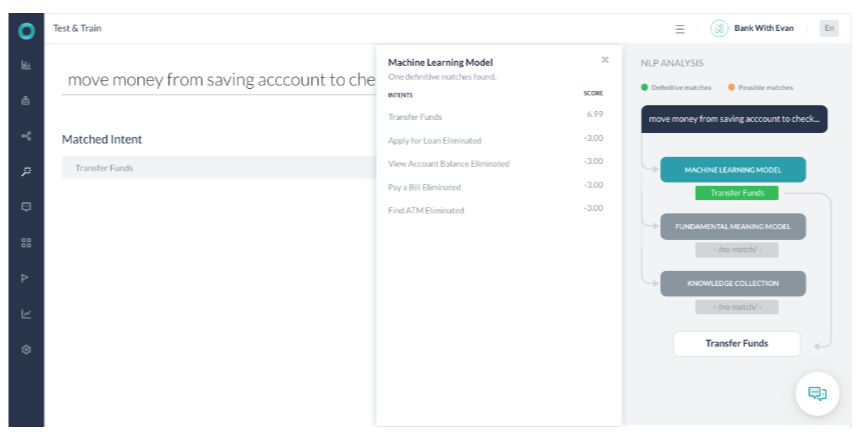
- ML 모델이 일치 항목이 없는 다른 모델의 확실한 일치를 반환하는 경우입니다.
- FM 모델은 작업 이름 자금 이체의 단어 중 사용자 발화의 단어와 일치하는 단어가 없기 때문에 이 작업을 식별할 수 없습니다.
시나리오 3 – 확실한 일치를 식별하는 KG
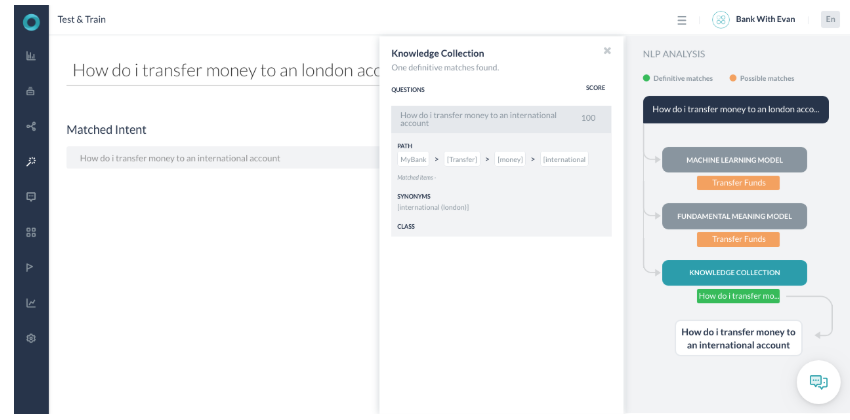
- 사용자 발화가 런던 계좌로 이체하려면 어떻게 해야 하나요?(How do I make transfer money to a London account?인 경우입니다.
- 사용자 발화에는 이 지식 그래프 의도 경로 이체(Transfer), 돈(Money), 국제(International)와 일치하는 데 필요한 모든 용어가 포함되어 있습니다.
- 국제(International)라는 용어는 사용자가 발화에서 사용한 런던의 동의어로 식별됩니다.
- 경로 용어가 100% 일치하므로 경로는 조건에 맞습니다. 신뢰도 스코어링의 일부로 사용자 질의의 용어는 실제 지식 그래프 질문의 용어와 유사합니다. 따라서 100점을 반환합니다.
- 반환된 점수가 100 이상이면 확실한 일치로 의도를 표시하고 선택합니다.
- FM 엔진은 핵심 용어 전송(Transfer)이 사용자 발화에 있으므로 가능한 일치로 찾았습니다.
- ML 엔진은 해당 발화가 학습된 발화와 완전히 일치하지 않았기 때문에 해당 발화를 가능한 일치로 찾았습니다.
시나리오 4 – 가능한 일치를 반환하는 여러 엔진
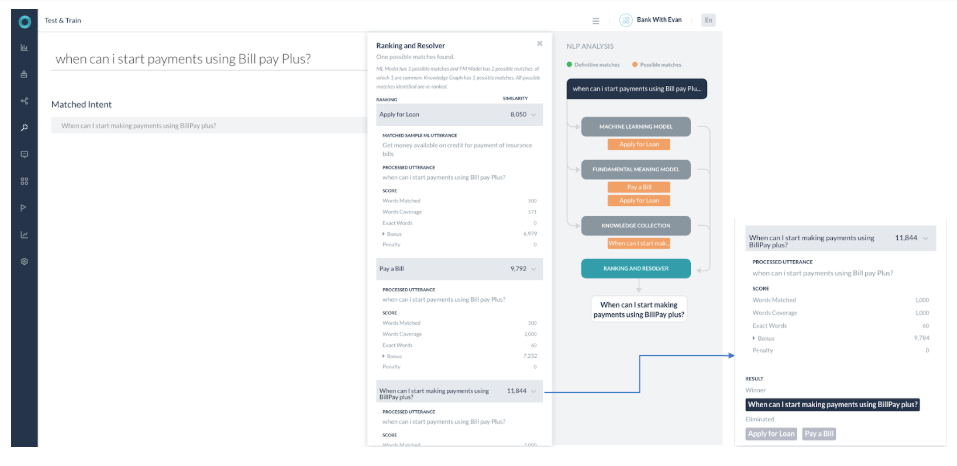
- 3개의 엔진 모두 가능한 일치를 반환했으며 확실한 일치는 반환하지 않았던 경우입니다.
- ML 모델에는 1개의 가능한 일치가 있고 FM 모델에는 2개의 가능한 일치가 있는데, 그 중 1개는 공통입니다. 지식 그래프에는 1개의 가능한 일치가 있습니다. 식별된 가능한 일치는 모두 순위 및 해결에서 다시 순위를 매깁니다.
- 순위 및 해결 구성 요소는 지식 그래프 엔진의 단일 일치(작업 이름 – BillPay plus로 언제부터 결제를 시작할 수 있습니까?(When can I start making payments using BillPay plus?))에서 가장 높은 점수를 반환했습니다. 다른 가능한 일치의 점수는 최고 점수의 2백분위수보다 낮으므로 무시됩니다. 이 경우 최종 결과는 'KG' 반환 질의이며 사용자에게 나타나게 됩니다.
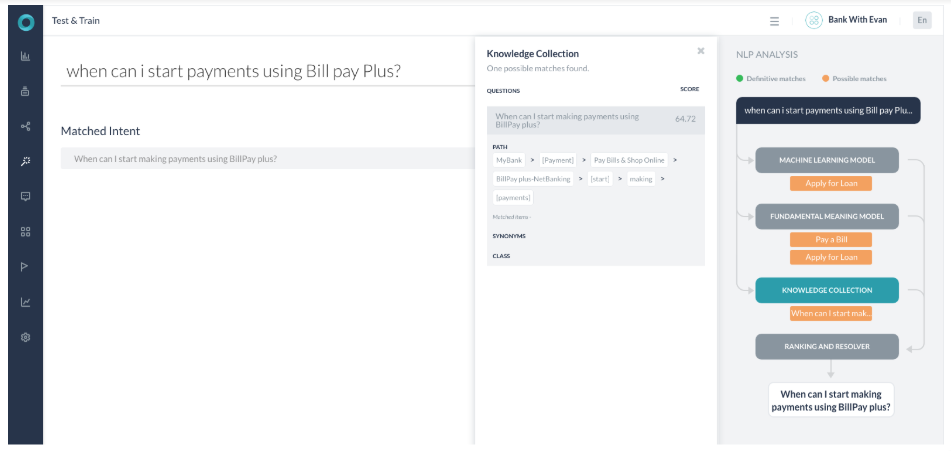
- 사용자 발화에 있는 대부분의 키워드가 KG 쿼리에 있는 키워드에 매핑되지만 여전히 이것이 확실한 일치는 아닙니다.
- 일치하는 경로 용어의 수가 100%가 아니기 때문입니다.
- KG 엔진은 64.72%의 확률로 점수를 반환했습니다. Billpay 대신 bill pay라는 단어를 사용했다면 점수는 87.71%였을 것입니다. (여전히 100% 일치는 아닙니다)
- 이제 점수가 60%-80% 사이에 있으므로 질의 임곗값이 완전한 최종 결과가 아니라 이런 뜻이 맞습니까 대화의 일부로 나타납니다. 점수가 80% 이상인 경우 플랫폼은 이런 뜻이 맞습니까 대화를 다시 확인하지 않고 응답을 제공했을 것입니다.
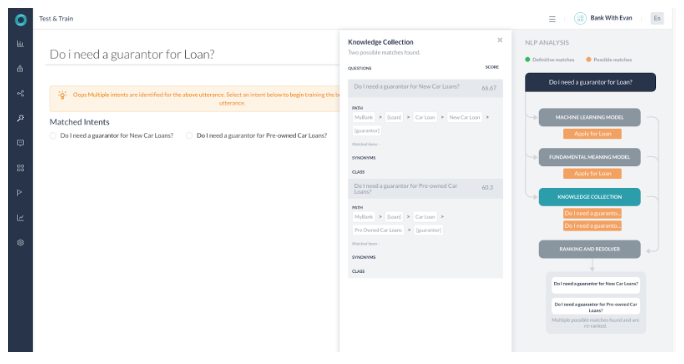
시나리오 5 – 여러 결과를 반환하는 해결
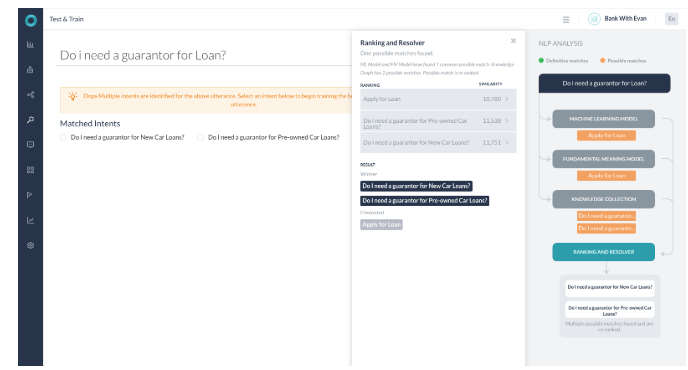
- 모든 엔진이 가능한 일치를 탐지했던 경우입니다.
- KG는 2개의 가능한 경로와 함께 반환되었습니다.
- 순위 및 해결은 점수 차이가 2% 미만인 질의 2개를 찾았습니다.
- 두 지식 그래프 의도를 모두 선택하여 사용자에게 이런 뜻이 맞습니까로 나타납니다.
- 두 경로 모두 두 일치 모두에서 용어로 선택되었으며 두 경로의 점수는 모두 60% 이상입니다.
시나리오 6 – 일치가 없음
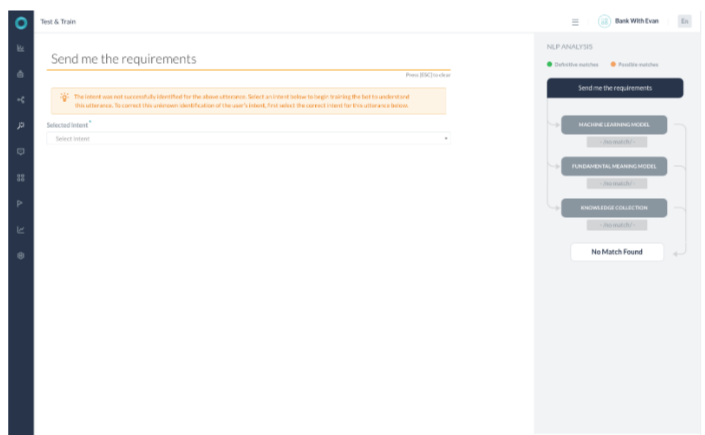
- 어떤 엔진도 학습된 의도 또는 지식 그래프 의도를 식별할 수 없었던 경우입니다.
- 이 시나리오에서는 기본 의도가 트리거됩니다.