지식 그래프는 CSV 또는 JSON 파일로 작성해 봇에 업로드할 수 있습니다. 마찬가지로 기존 지식 그래프를 CSV 또는 JSON으로 내보낼 수 있습니다. 지식 그래프를 내보내면 스프레드시트에서 편집하거나 다른 봇으로 가져올 수 있습니다. 최대 20k의 노드에 분산된 최대 50k개에 달하는 FAQ의 플랫폼 제한이 있습니다. 이 수를 초과하는 파일 가져오기는 거부됩니다.
지식 그래프 가져오기
- KG를 가져오기 원하는봇을 열고 빌드 탭을 선택합니다.
- 왼쪽 창에서 대화형 스킬> 지식 그래프를 클릭합니다.
- 가져오기 옵션은 각 지식 그래프에서 찾을 수 있습니다.

- 가져오기를 클릭합니다.
- 가져오기 대화 상자에서 다음 중 하나를 실행합니다.
- 지식 그래프를 처음부터 만들기 시작하는 경우 진행을 클릭합니다. (또는)
- 기존 지식 그래프가 있다면 해당 지식 그래프를 CSV 또는 JSON 파일로 백업한 다음 진행합니다.
참고 사항: 지식 그래프를 가져오면 업데이트되지 않고 기존의 전체 지식 그래프를 대체합니다.
- 가져오기 창에서 파일을 끌어서 놓거나 찾아보기를 클릭하여 파일을 찾습니다.
- 다음을 클릭하여 가져오기를 시작합니다.
- 가져오기를 완료하면 대화 상자에 성공 메시지가 표시됩니다. 완료를 클릭합니다.
- 계층이 지식 그래프에 표시되며 동일하게 편집하고 학습시킬 수 있습니다.
지식 그래프 내보내기
지식 그래프를 내보내려면 다음 단계를 따르십시오.
- 왼쪽 창에서 대화형 스킬 -> 지식 그래프를 클릭합니다.
- 내보내기 옵션은 각 지식 그래프에서 찾을 수 있습니다.
- 선호하는 형식에 따라 JSON 내보내기 또는 CSV 내보내기를 클릭합니다.
- 지식 그래프 파일이 컴퓨터에 다운로드됩니다.
지식 그래프 생성
플랫폼 UI에서 지식 그래프를 생성하는 대신, 스프레드시트나 JSON 파일과 같이 선호하는 편집기에서 작업할 수 있습니다. 플랫폼은 스프레드시트나 JSON에 지식 그래프를 생성하고 이를 사용하여 봇으로 가져올 수 있는 옵션을 제공합니다. 가져오려면 다음 단계를 따르세요.
- 샘플 CSV 또는 JSON 파일을 다운로드합니다. 비어 있는 지식 그래프에서도 이러한 샘플 파일을 다운로드할 수 있습니다.
- 질문, 응답, 동의어 등에 해당하는 행을 추가하여 파일을 편집합니다
- 파일을 봇으로 가져옵니다.
CSV 파일에서
귀하는 봇에서 다운로드할 수 있는 예제 스프레드시트를 사용하여 지식 그래프를 생성할 수 있습니다. 지식 그래프가 자주 변경될 것으로 예상되는 경우 애플리케이션 UI에 비해 대량 업데이트를 더 쉽게 수행할 수 있으므로 스프레드시트에서 생성하는 것이 좋습니다. 아래 지침에 따라 스프레드시트에서 지식 그래프를 작성합니다.
샘플 CSV 파일 다운로드
- 왼쪽 창에서 봇 작업> 지식 그래프를 클릭합니다.
- 가져오기 옵션은 각 지식 그래프에서 찾을 수 있습니다.
- 계속 진행하려면 지식 그래프를 백업하라는 메시지가 표시됩니다. 백업하려는 파일의 CSV 또는 JSON 형식을 선택합니다.
- 백업 후 진행을 클릭합니다.
- 해당 대화 상자에서 샘플 CSV를 클릭합니다. CSV 파일이 로컬 컴퓨터에 다운로드됩니다.
Build the Knowledge Graph in a CSV
The format for the CSV file includes details regarding alternate answers, extended responses, and advanced responses.
- The following types of entries are supported:
- Faq – The leaf level nodes with questions and answers.
- Node – For node/tags, traits, preconditions, and output context.
- Synonyms
- KG Params
- Traits
- Each of the above categories needs to be preceded by the appropriate header.
- The header helps identify the new vs old versions of the JSON file by the platform.
The following is the detailed information for each section and the content expected for each.
FAQ
This contains the actual questions and answers along with the alternate questions, answers, and extended answers.

Following are the column-wise details that can be given:
- Faq – Mandatory entry in the header, must be left blank in the following rows.
- Que ID – The Question ID is auto-generated by the platform. This field uniquely identifies the FAQs and it should not be added or edited manually. Leave this field blank if you are adding a new FAQ. Do not alter the value of this field if you are updating an existing FAQ. Do not manually add any data in this field.
- Path – To which the FAQ belongs
- Mandatory node names must be prefixed with ** and organizer nodes with !!
- Primary Question – The actual question user might ask: When left blank, the entry in the Answer column is considered as the alternative answer to the previous primary question.
- Alternate Question – Optional: Alternate question to the primary question if there are multiple alternate questions, they must be given in multiple rows.
- Tags – For each question or alternate question.
- Answer – Answer to the question serves as an alternate answer when the primary question field is left blank. Answer format can be:
- Plain text
- Script with SYS_SCRIPT prefix i.e.
SYS_SCRIPT <answer in javascript format> - Channel-specific formatted response when prefixed with SYS_CHANNEL_<channel-name>, the answer can be simple or in script format:
SYS_CHANNEL_<channel-name> SYS_TEXT <answer>SYS_CHANNEL_<channel-name> SYS_SCRIPT <answer in javascript format>
- Trigger a dialog then prefix with SYS_INTENT i.e.
SYS_INTENT <dialog ref id>
- Extended Answer-1: Optional to be used in case the response is lengthy.
- Extended Answer-2: Optional to be used in case the response is lengthy.
- ReferenceId – reference to any external content used as a source for this FAQ
- Display Name – The name that would be used for presenting the FAQ to the end-users in case of ambiguity.
Nodes
This section includes settings for both nodes and tags.

- Node – Mandatory entry in the header must be blank in the following rows.
- Que ID – The Question ID is auto-generated by the platform. This field uniquely identifies the FAQs and it should not be added or edited manually. Leave this field blank if you are adding a new FAQ. Do not alter the value of this field if you are updating an existing FAQ. Do not manually add any data in this field.
- Nodepath – Path for reaching the node/tag.
- Tag – Mandatory for tag settings, leave blank for node.
- Precondition – For qualifying this node/tag.
- outputcontext – Context to be populated by this node/tag.
- Traits – for this node/tag.
Synonyms
Use this section to enter the synonyms as key-value pairs.

- Synonyms – Mandatory entry in the header, must be blank in the following rows.
- Phrase – for which the synonym needs to be entered.
- Synonyms – Comma-separated values.
Use of bot synonyms in KG term identification can be enabled using the following:
- confidenceConfigs – Mandatory entry in the header, must be blank in the following rows.
- parameter – useBotSynonyms in this case
- value – true or false
KG Params
![]()
- KG Params – mandatory entry in the header, must be blank in the following rows.
- lang – Bot language code. For example, en for English.
- stopwords – Comma-separated values.
Traits
Trait related information can be specified as follows:

- Traits – Mandatory entry in the header, must be blank in the following rows.
- lang – Bot language code. For example, en for English.
- GroupName – Trait group name.
- matchStrategy – Pattern or probability (for ML-based).
- scoreThreshold – Threshold value (between 0 and 1) when the matchStrategy above is set to ML-based.
- TraitName – The name of the trait.
- Training data – Utterances for the trait.
For Taxonomy Based KG, the following fields can be included if there are one or more faqs linked to another faq in the KG. :
- faqLinkedTo – The faqLinkedto field identifies the source FAQ to which another FAQ is linked to. The faqLinkedTo field must contain a single, valid ‘Que ID’ of the source FAQ. ‘Que Id’ should be a valid identity generated by the platform. Do not give a reference to an FAQ that is already linked to another FAQ..
- faqLinkedBy – The faqLinkedBy field contains the list of ‘Que Ids’ of the FAQs that are linked to a particular FAQ. ‘Que Id’ should be a valid identity generated by the platform.
- isSoftDeleted – The isSoftDeleted field is used to identify the FAQs that are deleted but it has one or more FAQs linked to it.
JSON 파일
Kore.ai를 사용하면 지식 그래프를 JSON으로 생성하고 업로드할 수 있습니다. 봇에서 샘플 JSON을 다운로드하여 구조를 이해할 수 있습니다. 아래 지침에 따라 JSON을 사용하여 지식 그래프를 작성합니다.
JSON 샘플 다운로드
- 왼쪽 창에서 대화형 스킬 –> 지식 그래프를 클릭합니다.
- 가져오기 옵션은 각 지식 그래프에서 찾을 수 있습니다.
- 계속 진행하려면 지식 그래프를 백업하라는 메시지가 표시됩니다. 백업하려는 파일의 CSV 또는 JSON 형식을 선택합니다.
- 백업 후 진행을 클릭합니다.
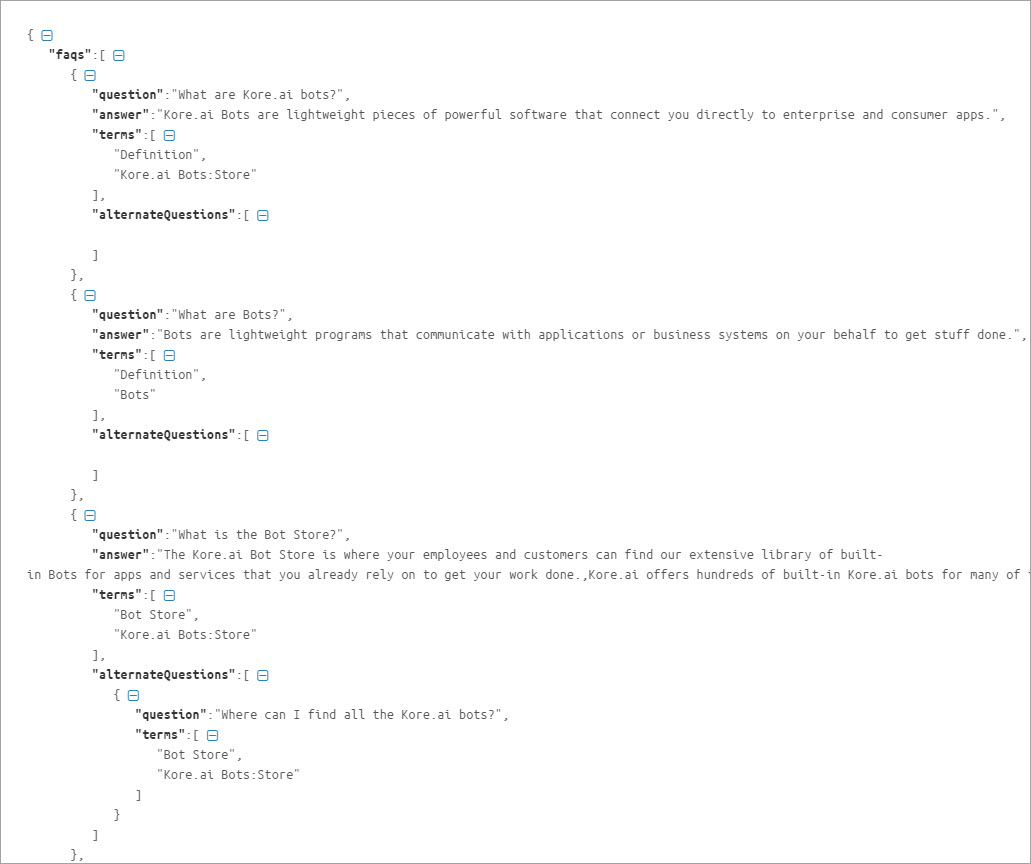
- 해당 대화 상자에서 샘플 JSON를 클릭합니다. JSON 파일이 로컬 컴퓨터에 다운로드됩니다.
JSON 참조
| 속성 이름 | 유형 | 설명 |
| FAQ | 배열 | 다음과 같이 구성됩니다.
|
| 질문 | 문자열 | 기본 질문은 FAQ 배열에 포함되어 있음. |
| 답변 | 문자열 | 봇 응답은 FAQ 배열에 포함되어 있음. |
| 용어 | 배열 | 질문이 추가된 리프 노드와 첫 번째 수준 노드까지의 부모 노드가 포함됩니다. |
| refId | 문자열 | 이 FAQ의 원본으로 사용되는 외부 콘텐츠의 선택적 참조 |
| 대체 질문 | 배열 | 대체 질문과 용어로 구성됩니다. 리프에서 첫 번째 수준 노드까지의 용어를 포함합니다. |
| 동의어 | 개체 | 용어 및 해당 동의어의 배열로 구성됩니다. |
| Unmappedpath | 배열 | 질문이 없는 노드 배열과 첫 번째 수준 노드까지의 모든 상위 부모 노드로 구성됩니다. |
| 특성 | 개체 | 특성 이름을 키로 구성하고 발화 배열을 값으로 구성합니다. |
분류법 기반 KG의 경우 KG의 다른 FAQ에 연결된 FAQ가 하나 이상 있는 경우 다음 필드를 포함할 수 있습니다. :
- faqLinkedTo – 원본 FAQ를 식별합니다.
- faqLinkedBy – 연결된 FAQ를 식별합니다.
- isSoftDeleted – FAQ를 식별하기 위해 삭제되었지만 일부 연결된 FAQ가 있습니다.