
The Knowledge Graph Extraction Service enables you to effortlessly move your enterprise’s existing Frequently Asked Questions- FAQ content – into bot Knowledge Graph.
The feature supports the extraction from unstructured content such as web pages and PDF documents as well as from structured content such as CSV files.
After completing the extraction, you can edit the question and answers using an easy-to-use interface and organize them under the relevant Knowledge Graph nodes.
Extraction Process
Moving data using the Knowledge Extraction Service to the Knowledge Graph involves the followings steps:
- Step 1 Extracting: Extract the existing FAQ content from structured or unstructured sources of question-answer data such as PDF, web pages, and CSV files. This extraction can be done before or after creating a Knowledge Graph for the bot.
Note: The Knowledge Extraction service supports a specific content structure for each source type. Refer to the Supported formats section for details.
- Step 2 Editing: Upon successful data extraction, you can edit the questions and answer text before moving it to the Knowledge Graph.
- Step 3 Moving: You can add data into a Bot before or after creating a Knowledge Graph (KG). If you try to add the extracted content to a KG before it exists, the bot creates automatically create one with the Bot’s name.
The Knowledge Extractor allows you to add the extracted content to the Knowledge Graph:
- Add to Knowledge Graph moves the selected questions to the root node of the Knowledge Graph. You can use this option when the required term is not yet added to the KG or when the Bot does not have a Knowledge Graph.
- Add to Specific Term: If the bot already consists of a Knowledge Graph, you drag-drop the selected content to the required nodes.
Extracting from a Website
- Open the bot into which you want to extract the content and click the Knowledge Graph tab.
- Under Extracts section, click Extract from URL.
- Enter a Name for extraction.
- Enter the URL of the page, and then click Proceed.

- Once the extraction is complete, the page with the Success status appears.
Extracting from File
NOTE: File size should not be more than 5MB.
For file format details, refer to the Supported formats section below.
- Open the bot into which you want to extract the content and click the Knowledge Graph tab.
- From the Extracts section, from the tab Extract from file, click Browse.
- Browse to the file – PDF or CSV formatted, select the file and then click Proceed.
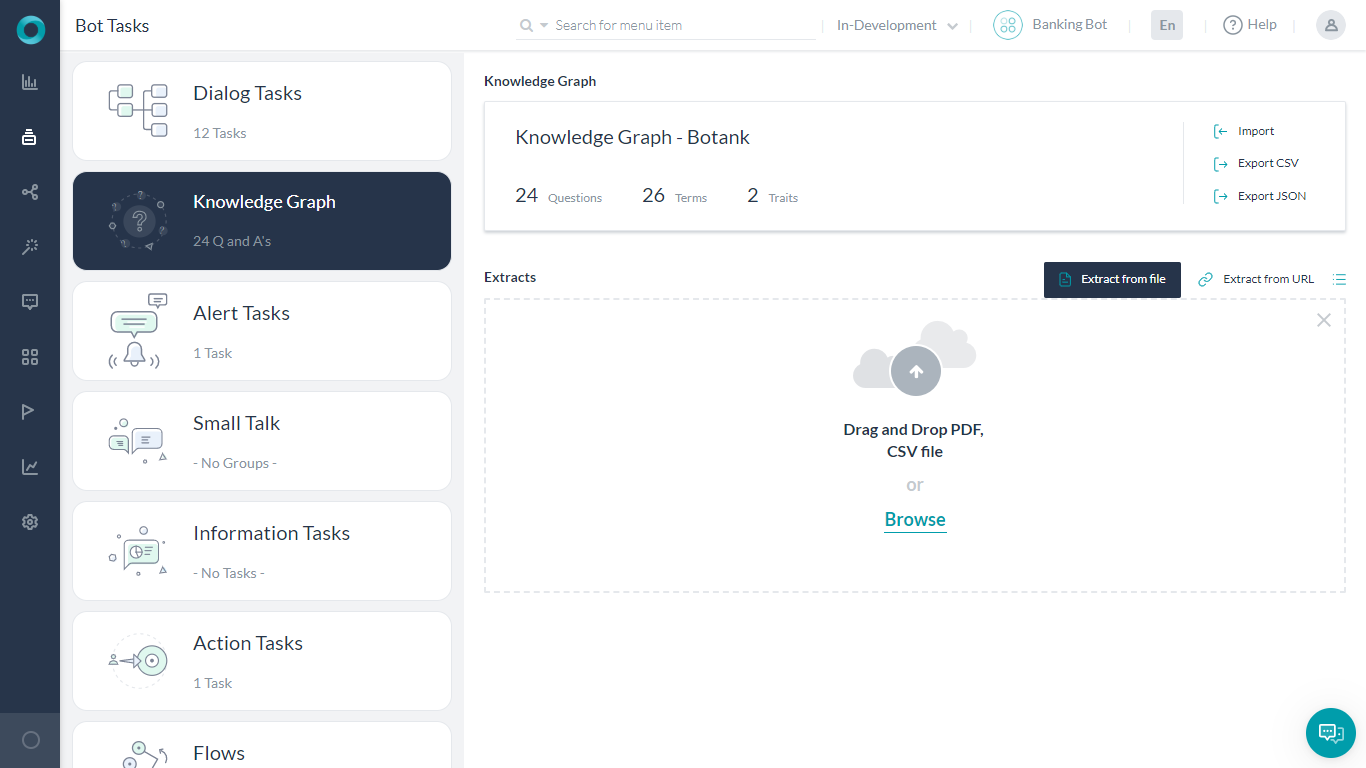
- Once the extraction is complete, a page with the Success status will be displayed.
Editing the Extracted Content
- Open the bot and click the Knowledge Graph tab.
- The Knowledge Extraction section displays the list of all extractions.
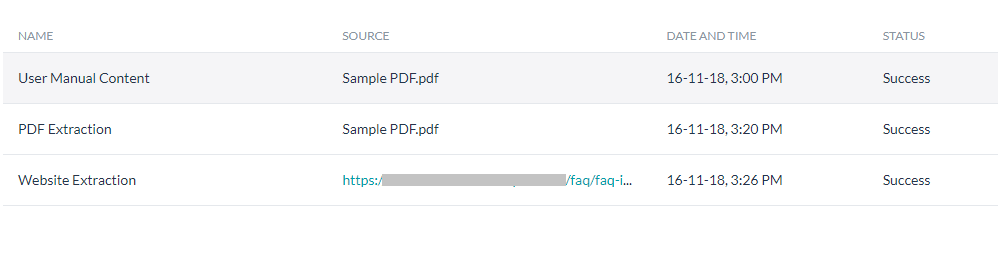
- Click the name of a successful extract whose content you want to edit.
- Hover over the question-answer pair to modify it and click the edit icon.
- Make the necessary changes and click Save.
Adding the Extracted Content
There are two ways to add the extracted content to the Knowledge Graph.
From the Extracts Section
- Open the bot and click the Knowledge Graph tab.
- From the Knowledge Extraction section, select the name of a successful extract whose content you want to add.
- Drag and drop the required Q&A to the node/term to which you want to add. As you drag and drop the child nodes will be expanded.
- You can select multiple Q&As and do a bulk move.
From Knowledge Graph
- Open the bot and click the Knowledge Graph tab.
- Select the node to which you want to add these Question-Answers.
- Click Add from extraction. It opens the list of successful and failed extractions.
- Click the name of a successful extract whose content you want to move.
- Select the checkboxes next to the question-answer pairs that you want to move and then click Add.
Note: Once you move a question-answer pair from the extract to the knowledge graph, you cannot move it again. The platform throws a duplicate error when you try to move a question from the extract that’s already present in the collection. You can make any changes to the moved content from the knowledge graph. However, if the question is modified or removed in the knowledge graph, then the developer would be allowed to add it again to the knowledge graph.
Supported Formats
The Knowledge Extraction service supports extracting FAQs only from supported CSV, PDF and URL formats.
Note that the file size should not be more than 5MB.
CSV
- The Knowledge Extraction service interprets the text in the first column as a question and that in the second column as an answer.
- The file should not have any headers.
- The Knowledge Extraction service ignores any headers and the text present in the other columns.
- The Knowledge Extraction service can process the content from a PDF and convert into question-answer pairs.
- Documents with table of contents: Ideally a document with a table of contents is preferred. In such cases, the Knowledge Extraction service extracts the table of contents first and then uses it to parse the document and identify headings. The information present in the table of contents is used to derive the hierarchy of headings (headings. subheadings, sub-subheadings, etc.). These levels will be separated by a vertical line as a delimiter (heading | subheading | sub-subheading) as part of the extraction process.
- Documents with no table of contents: In such cases the Knowledge Extraction service uses a pre-trained machine learning model that identifies headings based on either font style or font size. In case of using font size, the heading hierarchy can also be derived.
- The text is then formatted with uniform header and paragraph blocks.
Web Pages
The Knowledge Extraction service supports the following three different formats of FAQ web pages:
- Plain FAQ Pages with linear question-answer pairs
- Pages with question hyperlinks that point to answers on the same page.
- Pages with question hyperlinks that point to answers on a different page.
Extraction of certain FAQs on the webpage fails under the following conditions:
- The question text is split between multiple HTML tags on the FAQ page.
- The tag applied to the answer is neither the child nor the sibling of the extracted question as per the HTML DOM structure.
- The question doesn’t have a hyperlink to the answer (applies to FAQs with hyperlinks)
- When the questions hyperlink to the answer, but the question statement isn’t repeated above the answer (applies to FAQs with hyperlinks)
The extraction of the entire FAQ page fails if the page consists of more than one FAQ page types mentioned above.