Botが関連するタスクでユーザーの発話にBotが応答することを確認するには、さまざまなユーザー入力でBotをテストすることが重要です。予想されるユーザー入力の大規模なサンプルを使用してBotを評価することによって、Botの応答に関する洞察が得られるだけでなく、多様な人間の言い回しを解釈するBotをトレーニングする絶好の機会が得られます。
Botのトレーニング関連のすべてのアクティビティは、発話テストモジュールから実行することができます。ここでは、テストとトレーニングの記事全体で例として、次のタスクで構成されるフライト予約Botのサンプルを使用します。
Botのテスト
簡単に言えば、BotのテストとはBotがユーザーの発話に最も関連性の高いタスクで応答できるかどうかを確認することです。言語の柔軟性を考えると、ユーザーは同じインテントを表現するために幅広いフレーズを使用することになります。
たとえば、1月1日のサンフランシスコからロサンゼルスへのチケットを変更したいを旅行日を変更したいと言い換えることができます。1月1日には間に合いません。コツとしては、これらの発話の両方を同じインテントまたは予約の変更タスクとしてとらえるようにBotをトレーニングすることです。
したがって、Botのテストを開始する最初のステップとしては、Botの応答をテストするためのユーザーの発話の代表的なサンプルを特定することです。サポートチャットログ、オンラインコミュニティ、関連するポータルのFAQページなど、実際の言語の使用状況を反映したデータソースを探します。
Botのテスト方法
Botをテストするには次の手順に従ってください。
- テストするBotを開きます。
- 左側のナビゲーションパネルからテストにカーソルを合わせ、発話テストをクリックします。
- 複数インテントのモデルがある場合、発話をテストしたいインテントを選択することができます。機械学習エンジンは、選択したモデルからのみインテントを検出します。
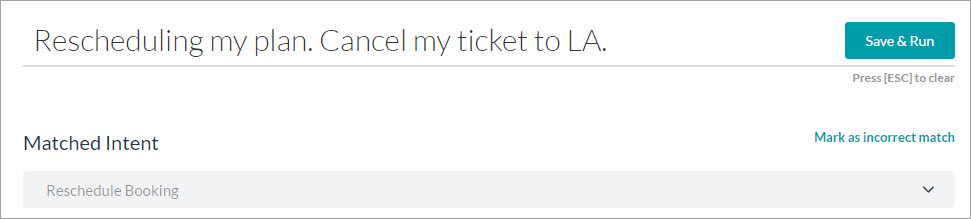
- ユーザーの発話を入力フィールドの中に、テストしたい発話を入力します。例:予定を再スケジュールする。LA行きのチケットをキャンセルする。
- 結果は、単一,複数のインテントがある場合、または一致するインテントがない場合に表示されます。
テスト結果の種類
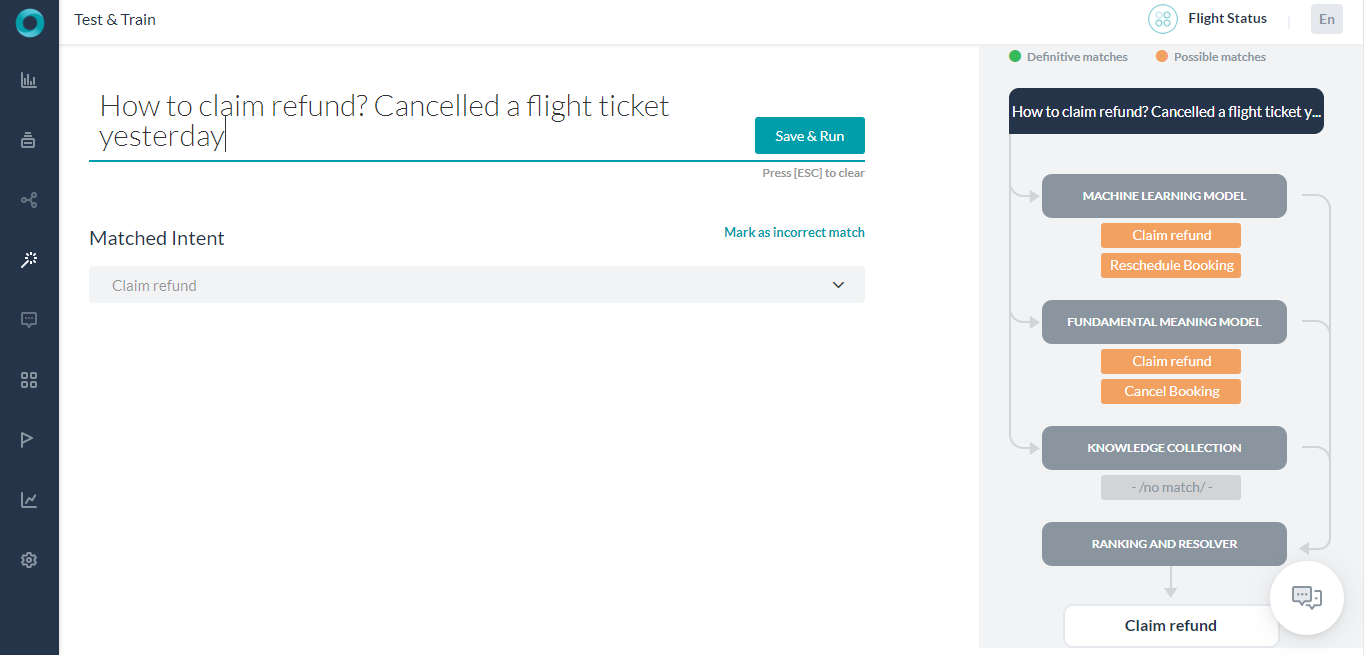
Botに対してユーザーの発話をテストすると、NLPエンジンはそのインテントに一致するBotタスクを見つけようとします。NLPエンジンは、機械学習、ファンダメンタルミーニング、ナレッジグラフ(Botがある場合)モデルを使用したハイブリッドアプローチを使用して、一致するインテントを関連性でスコア化します。このモデルは、ユーザーの発話を一致の可能性または完全一致のいずれかに分類します。
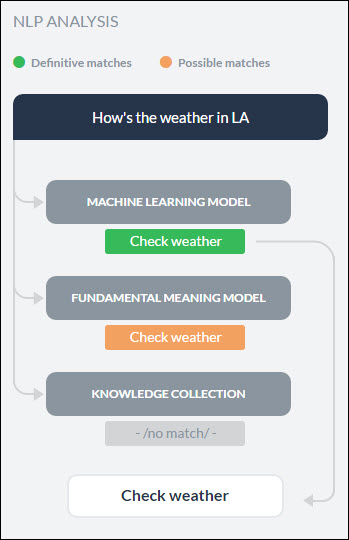
完全一致では、確信度の高いスコアが得られ、ユーザーの発話に完全に一致すると見なされます。公開済みのBotでは、ユーザー入力が単一の完全一致と一致する場合、Botはタスクを直接実行します。発話が複数の完全一致と一致する場合、エンドユーザーが選択できるオプションとして送信されます。
一方、一致の可能性はユーザー入力に対して適度にスコアが高いものの、完全一致と呼ぶには十分な確信度が足りないインテントのことです。内部的には、システムはスコアに基づいて、一致の可能性を優れた一致と不確かな一致に分類します。エンドユーザーの発話が公開済みのBotで一致の可能性を生成していた場合、Botはこれらの一致をエンドユーザーへの提案としてもしかして?と送信します。
以下は、ユーザーの発話テストで考えられる結果です。
- 単一の(一致の可能性または完全一致):NLPエンジンは、単一のインテントまたはタスクのあるユーザーの発話に一致するものを見つけます。インテントは、ユーザー発話フィールドの下に表示されます。適切な一致である場合は、次の発話のテストに進むか、タスクをさらにトレーニングしてスコアを向上させることができます。不適切な一致である場合は、不適切としてマークして適切なインテントを選択できます。
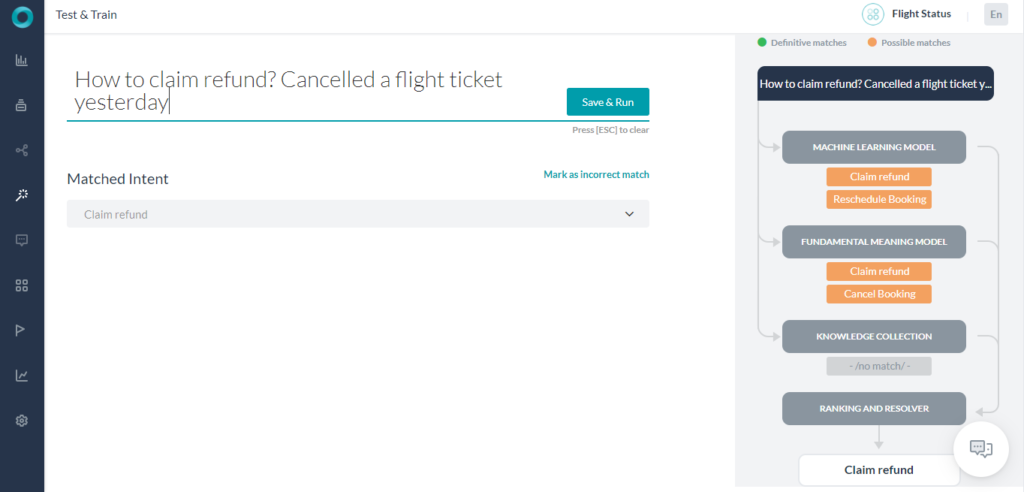
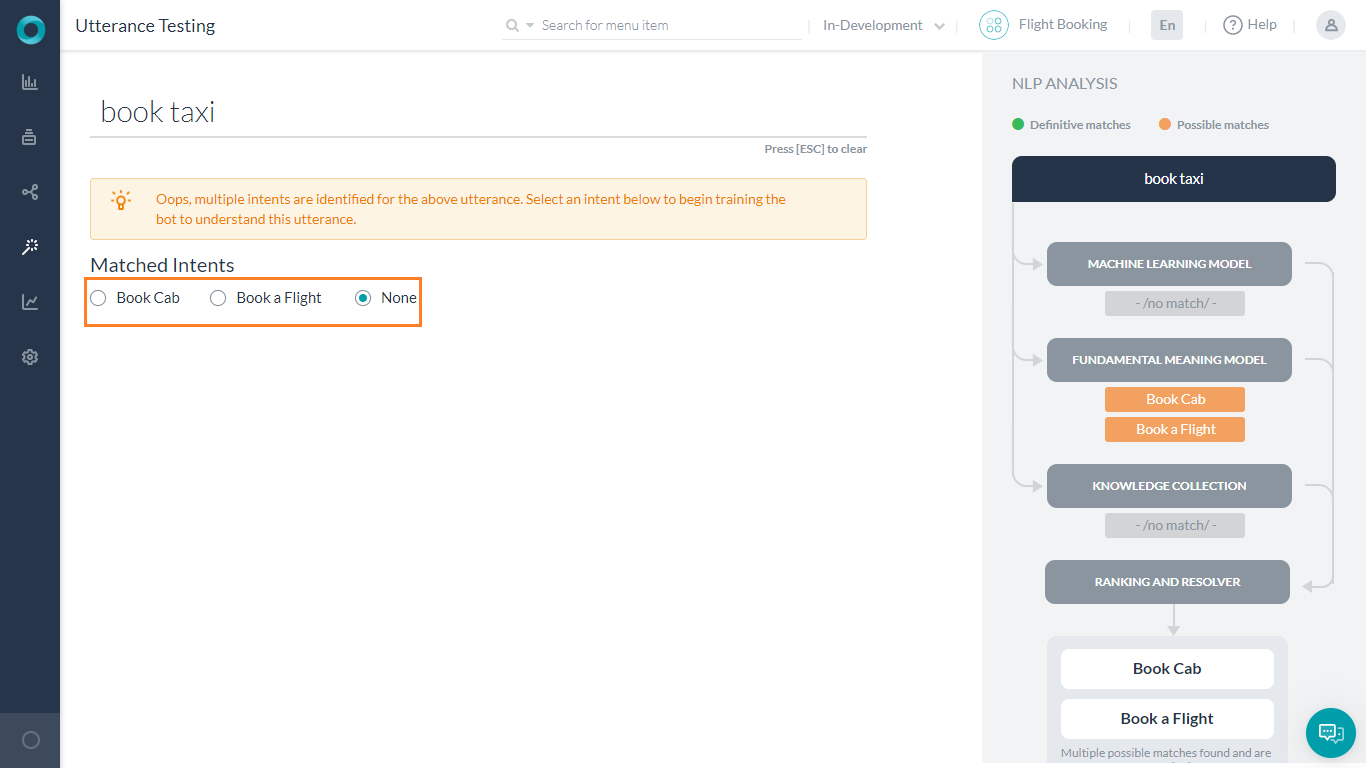
- 複数の一致(一致の可能性または完全一致またはその両方):NLPエンジンは、ユーザーの発話と一致する複数インテントを特定します。結果から、一致するタスクのラジオボタンを選択してトレーニングします。
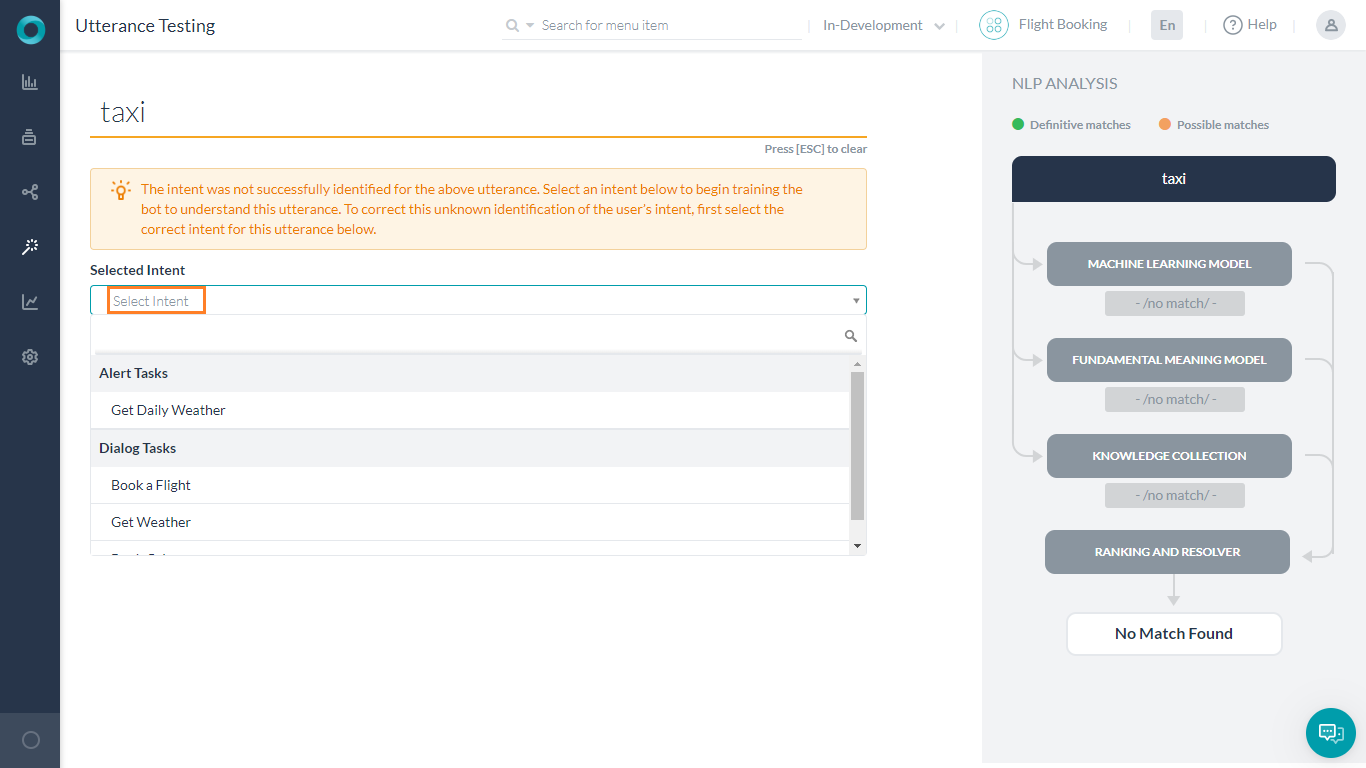
- 未特定のインテント:ユーザー入力は、リンクされたBotのいずれのタスクとも一致しませんでした。インテントを選択し、ユーザーの発話に一致するようにトレーニングします。
エンティティの一致
Botのテスト中に、一致したエンティティが表示されます。発話からのエンティティは、最初にNERとパターンエンティティ、次に残りのエンティティの順序で処理されます。
プラットフォームのリリース8.0以降では、エンティティがどのように一致したか、およびどの確信スコアと一致したかという詳細も表示されます。詳細は次のとおりです。
- 特定エンジン-機械学習またはファンダメンタルミーニング
- トレーニングタイプ-NER、パターントレーニング、エンティティ名、システムコンセプトなどから一致を行うことができます。パターンが一致する場合は、行をクリックすると同様に詳細が表示されます。
- NERトレーニングを使用して機械学習エンジンによって特定された確信度スコアです(条件付きランダムフィールドがNERモデルとして選択されている場合のみ)。

テスト結果の分析
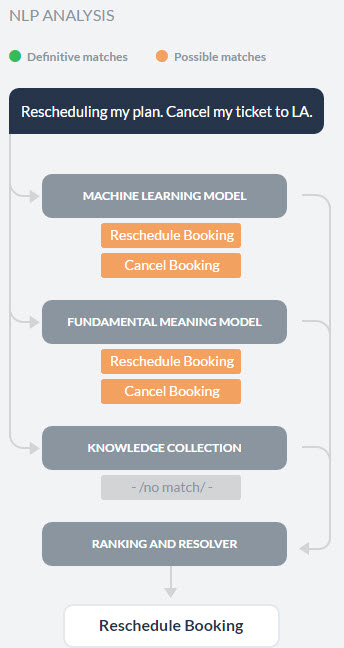
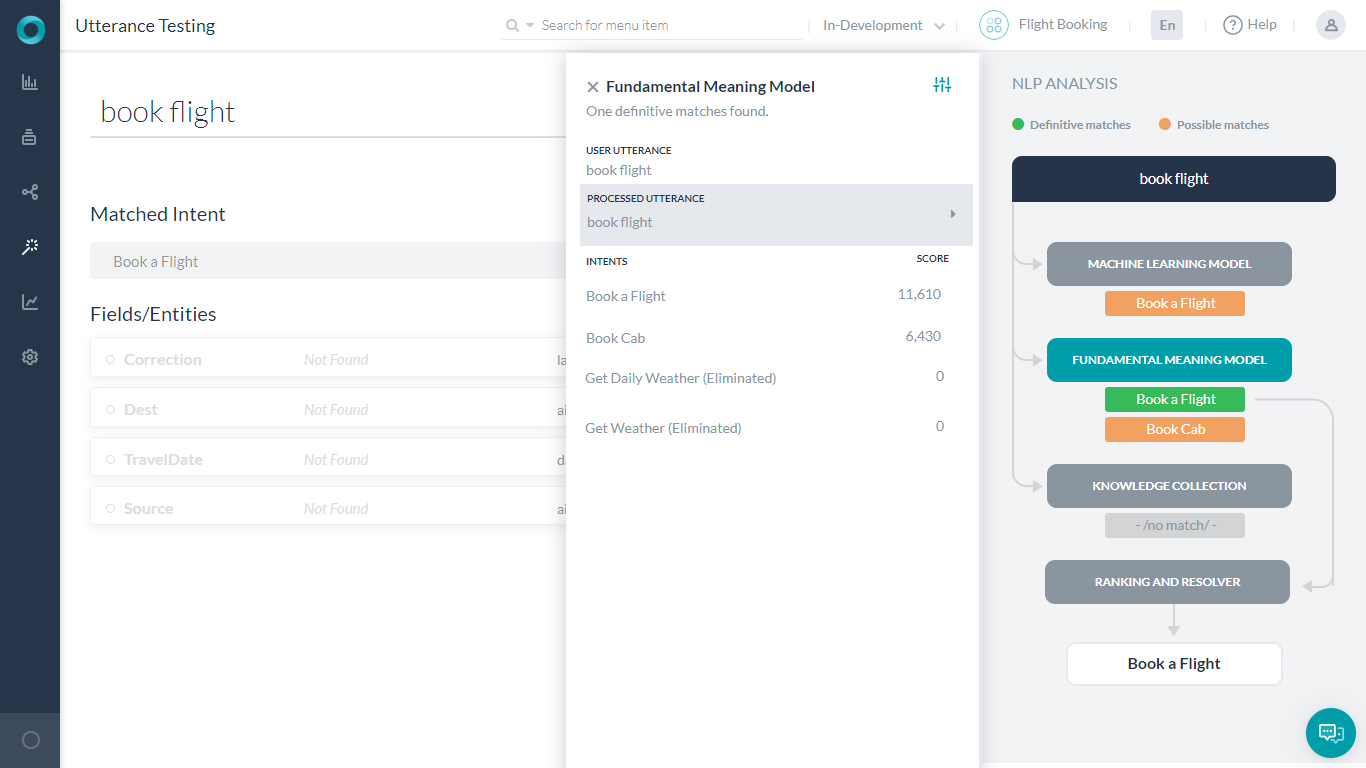
ユーザーの発話をテストすると、一致するインテントに加えてNLP分析ボックスも表示され、候補リストのインテント、候補リストに挙がったインテントを使用したNLPモデル、対応するスコア、最終的な勝者の概要が表示されます。
ファンダメンタルミーニングタブの下では、候補リストに含まれていなくてもすべてのインテントのスコアを確認できます。
前述のように、Kore.ai NLPエンジンは、機械学習、ファンダメンタルミーニング、ナレッジグラフ(存在する場合)のモデルを使用してインテントを一致させます。NLPエンジンが単一の完全一致 を見つけた場合、基礎となるモデルの1つを介して、そのタスクは一致するインテントとして表示されます。テストで複数の完全一致が検出された場合、適切なインテントを選択するためのオプションとして受け取ります。
モデルが複数の一致の可能性を候補リストに挙げた場合、リストアップされたすべてのインテントは、ファンダメンタルミーニングモデルを使用して、ランキングおよび解決によって再スコアリングされ、最終的な勝者が決定されます。
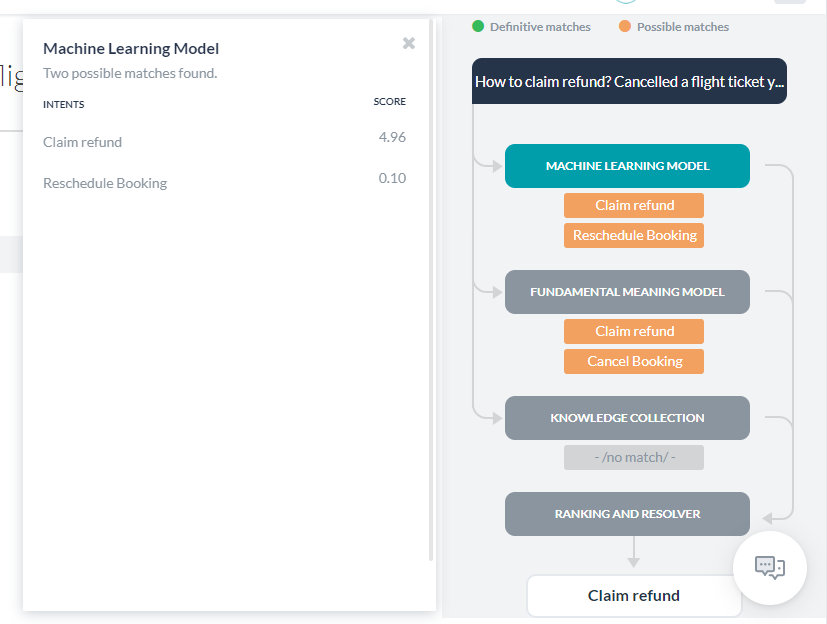
場合によっては、複数の一致の可能性が再スコアリング後も同じスコアを確保することがあります。その場合は複数の一致として表示され、開発者は1つを選択することができます。NLP分析ボックスの学習モデル名が付いたタブをクリックすると、インテントスコアが表示されます。
各モデルダイアログで右上のアイコンをクリックすると、対応するエンジンの設定としきい値が表示されます。
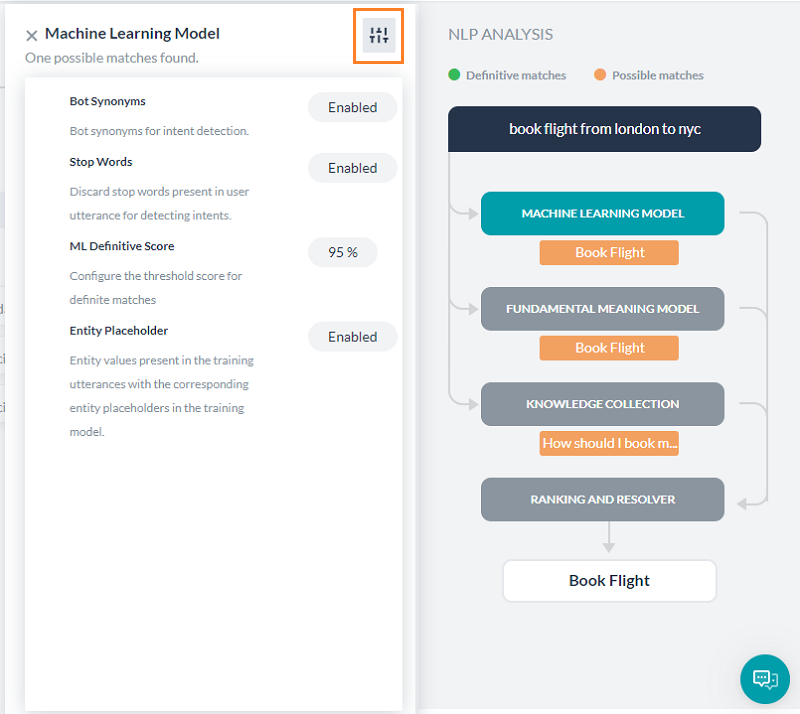
機械学習モデル
機械学習モデルは、ユーザー入力をタスクラベルおよび各タスクのトレーニング発話と一致させようとします。ユーザー入力が複数の文から構成されている場合、各文はタスク名とタスクの発話に対して個別に実行されます。
機械学習モデルボタンをクリックして、NLP分析の機械学習モデルセクションを開きます。これは、ポジティブスコアを確保したタスクの名前のみを表示します。一般に、タスクに追加するトレーニング発話の数が多いほど発見される可能性が高くなります。詳細については、機械学習を参照してください。
FMモデル
機械学習モデルとは別にBot内の各タスクは、タスク名、同義語、パターンのさまざまな組み合わせを含む包括的なカスタムNLPアルゴリズムを使用して、ユーザー入力に対してスコアリングされます。
ファンダメンタルミーニング(FM)モデルタブには、Bot内のすべてのインテントの分析が表示されます。タブをクリックすると各タスクのスコアが表示されます。
処理済みの発話をクリックすると、ユーザーの発話がどのように分析および処理されたかが表示されます。
リリース7.2以降では、FMエンジンはBotの言語に応じて2つの方法でモデルを生成します。
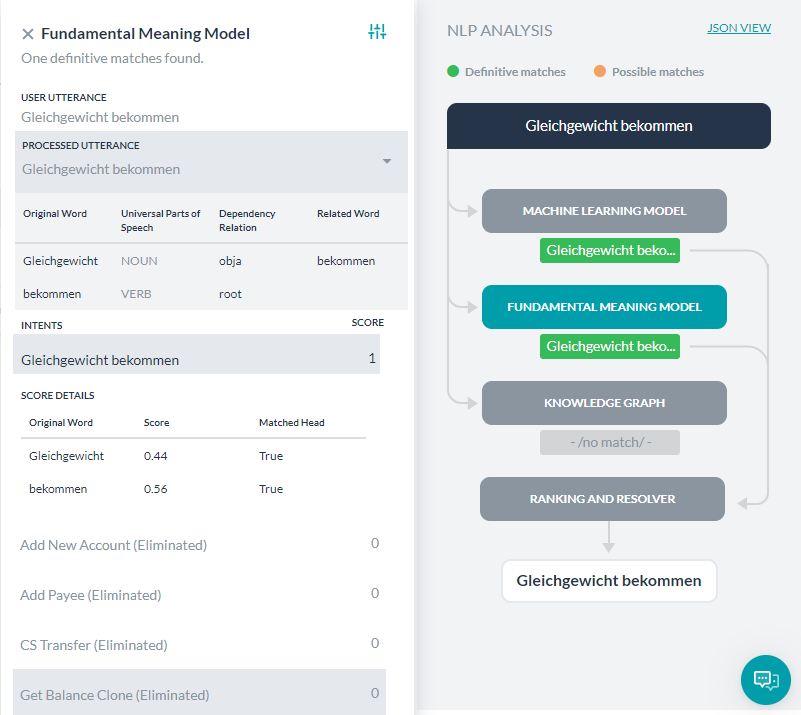
アプローチ1:ドイツ語とフランス語でサポートされています。
単語分析要素では、原語、普遍的な品詞、従属関係、関連語に関して詳しく説明しています。
次に、処理済みの各インテントごとにスコア詳細が表示されます。スコアリングされたインテント(一致または削除)を選択すると、各単語のスコアリングの詳細が表示されます。これには、発話された単語と、依存関係の解析に基づいてそれぞれに割り当てられたスコアが含まれます。
アプローチ2:上記以外の言語でサポートされています。
単語分析要素では、原語、文中での役割、処理済みの単語(スペル修正の場合)に関して詳しく説明しています。
次に、処理済みの各インテントごとにスコア詳細が表示されます。スコアリングされたインテント(一致または削除)を選択すると、各単語のスコアリングの詳細が表示されます。内訳の詳細は以下のとおりです。
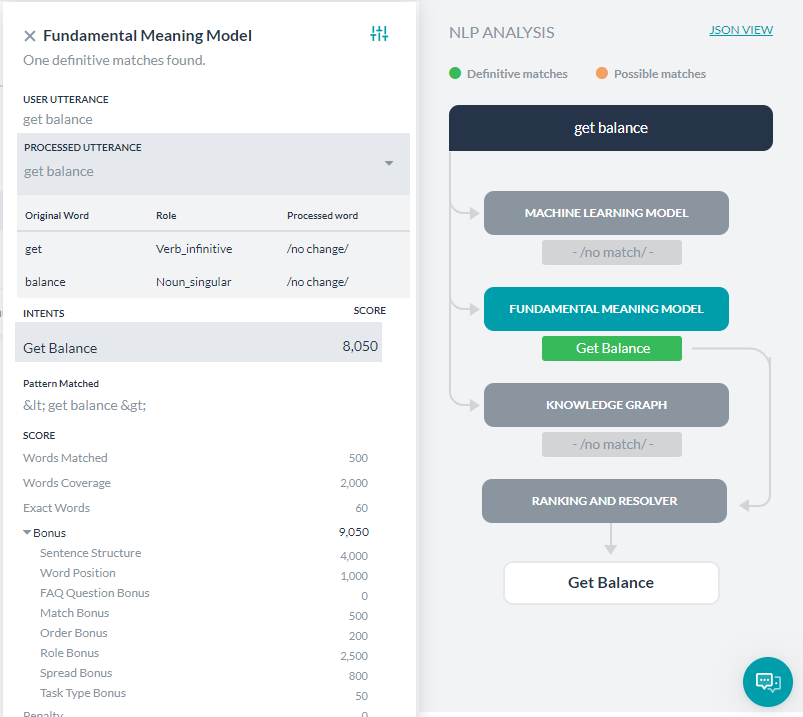
- 単語一致:タスク名またはトレーニングされたタスクの発話に一致するユーザー入力の単語数に与えられるスコアです。
- 単語の範囲:タスク名、フィールド名、発話、同義語など、タスク内の全体的な単語と一致する単語の割合を示すスコアです。
- 正確な単語:同義語ではなく、完全に一致した単語の数に対して与えられるスコアです。
- ボーナス
- 文の構造:ユーザー入力の文構造と一致した場合にボーナスが発生します。
- 単語の位置:文中での位置に基づいて単語に与えられるスコアは、文の先頭の方に来る個々の単語が優先してスコアを得られます。単語が文頭に近い場合は、追加的なクレジットが得られます。
- オーダーボーナス:タスクラベルと同じオーダーの単語数にボーナスが与えられます。
- 役割ボーナス:一次および二次的役割(主語/動詞/目的語)が一致している数に応じてボーナスが与えられます。
- スプレッドボーナス:パターン内の最初と最後に一致した単語の位置の差に与えられるボーナスです。差が大きいほど、スコアは大きくなります。
- ペナルティ:タスク名の前に複数のフレーズがある場合、またはタスクラベルの途中に接続詞がある場合にペナルティが発生します。
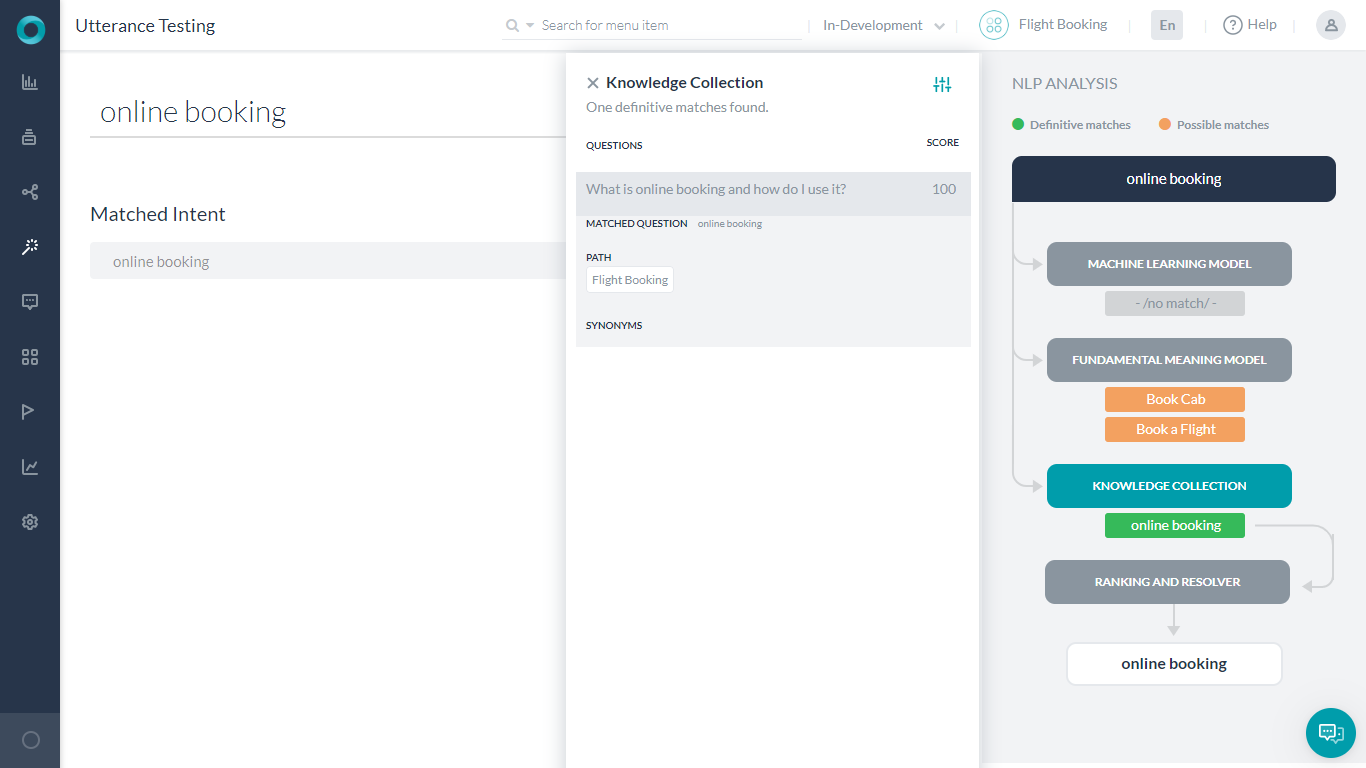
ナレッジグラフ
Botがナレッジグラフで構成されている場合、ユーザーの発話は用語を抽出するために処理され、関連するパスを取得するためにナレッジグラフにマッピングされます。事前設定されたしきい値を超える用語数を含むすべてのパスは、さらにスクリーニングするために候補リストに入れられます。100%の用語がカバーされ、パス内に類似のFAQがあるパスは、完全に一致すると見なされます。
発話がダイアログをトリガーする場合(ナレッジグラフでダイアログオプションを実行するなど)、一致したインテントおよび一致した発話として同じものが表示されます。以下のトレーニングセクションで詳しく説明しているように、機械学習またはFMエンジンからのインテントの場合と同じように、Botをさらにトレーニングすることができます。
ランキングおよび解決
ランキングおよび解決は、NLP計算全体の最終的な勝者を決定します。機械学習モデルまたはナレッジグラフのいずれかが完全一致を見つけた場合、ランキングおよび解決はインテントを再スコアリングせず、一致したインテントとして表示します。完全一致が複数ある場合でも、開発者が選択できるオプションとして表示されます。
ランキングおよび解決は、ファンダメンタルミーニングモデルを使用して3つのモデルによって特定された他のすべての優れた一致と不確かな一致を再スコアリングします。再スコアリング後にインテントの最終スコアが特定のしきい値を超えると、それも一致と見なされます。
ランキングおよび解決タブを選択すると、詳細が表示されます。
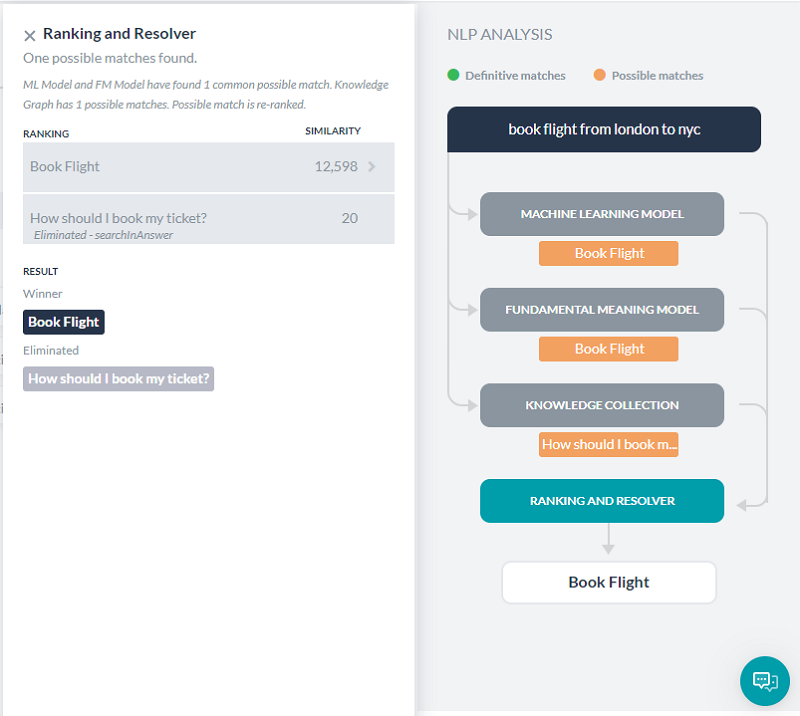
一致した発話を選択すると、それぞれの一致したランキングと詳細を表示できます。
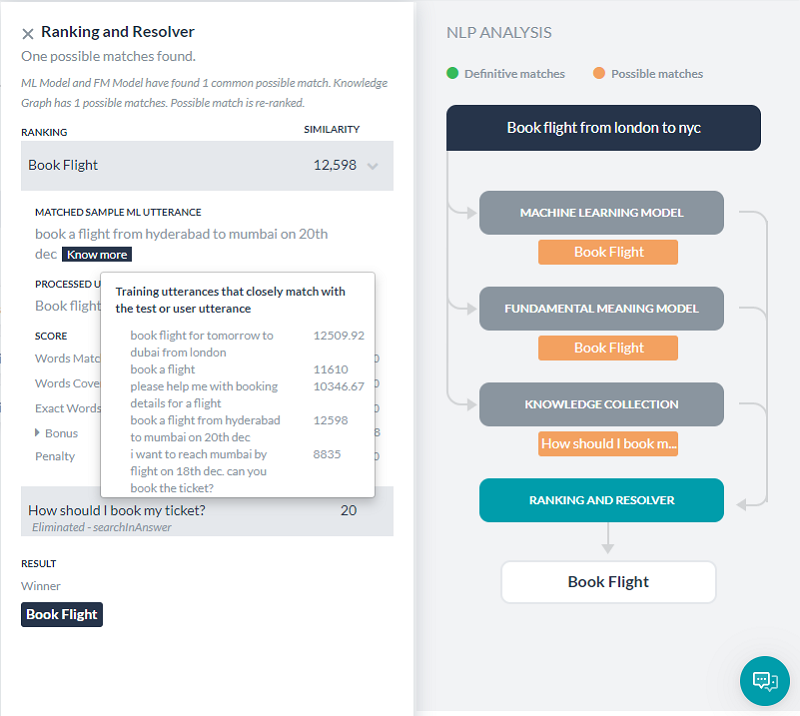
Bot言語に応じて、スコアリングモデルは次のようになります。
- 単語の役割、文/単語の位置、語順の組み合わせに基づいています。
- 依存関係の解析に基づいています(ドイツ語とフランス語でサポートされています)。
3つのエンジンが異なる明確な一致の可能性を返す場合のランキングおよび解決によるインテントの削除の基準は次のとおりです。
- 機械学習モデルによって、日付、数字などのエンティティ値に基づいて一致したインテントは削除されます。
- 完全一致が見つかった場合、3つのエンジンのいずれかによって特定されたすべての一致の可能性が削除されます。
- ユーザーの発話でこれより前に別の完全一致が見つかった場合、ユーザーの発話に2つのインテントが含まれている際は完全一致は削除されます。たとえば、「フライトを予約してからタクシーを予約する」は「フライトの予約」と「タクシーの予約」に一致しますが、「フライトの予約」に続いている「タクシーの予約」が削除されます。
- 完全なインテントの一致に続くインテントパターンの一致は削除されます。たとえば、「メールを送信するタスクを作成する」というユーザーの発話は、「タスクを作成する」と「メールを送信する」というインテントに一致する可能性があります。この場合、「メールを送信する」は「タスクを作成する」というインテントに続くため削除されます。
- スコアが、しきい値と設定セクションで設定された最小値を下回るインテントは削除されます。
- ネガティブパターンに一致する完全一致。
- 定義されている場合、前提条件が満たされていないインテントは削除されます。
- 完全一致がナレッジグラフエンジンのSearch In Answerからのものであり、他にも一致するインテントがある場合。
Botのトレーニング
トレーニングとは、ユーザー入力に基づいてあるBotのタスクまたはユーザーのインテントを別のBotタスクよりも優先させるために、NLPエンジンのパフォーマンスを向上させる方法です。考えられるすべてのユーザーの発話と入力についてBotをテストし、必要に応じてトレーニングを行う必要があります。
Botのトレーニング
- ユーザー発話を入力した後、テスト結果に応じて次のいずれかを実行してトレーニングオプションを開きます。
- 一致のないインテントの場合:インテントを選択ドロップダウンリストから、ユーザーの発話と一致させるインテントを選択します。
- 複数の一致したインテントがある場合:一致させたいインテントのラジオボタンを選択します。
- 単一の一致したインテントがある場合:一致したインテントの名前をクリックします。
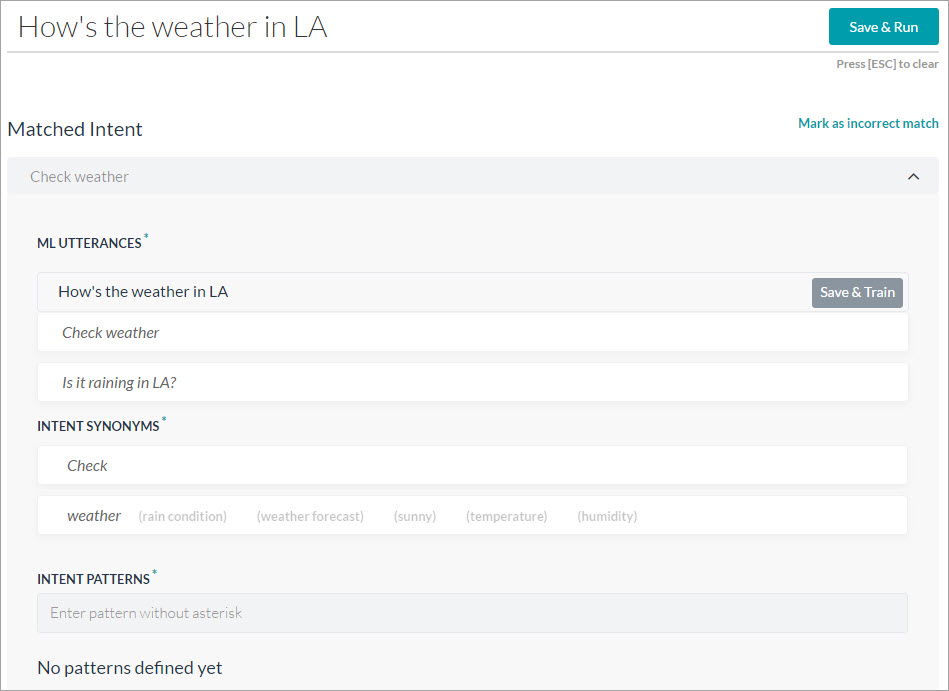
- 入力したユーザーの発話が機械学習発話セクション下のフィールドに表示されます。発話をインテントに追加するには、保存してトレーニングするをクリックします。必要な数の発話を次々に追加することができます。詳細については、機械学習を参照してください。
- インテントの同義語セクションでは、タスク名の各単語が個別の項目として表示されます。単語の同義語を入力して、NLPインタープリターが正しいタスクを認識する精度を最適化します。詳細については、同義語の管理をご覧ください。
- インテントパターンセクションで、インテントのタスクパターンを入力します。詳細については、パターンの管理をご覧ください。
- 関連するトレーニング項目の作成が完了したら、発話の再実行をクリックして、高い信頼スコアを取得するためにインテントが改善されたかどうかを確認します。
FAQでのトレーニング
Botがユーザーの発話にFAQで応答するようにしたい場合は、次の2つの方法があります。
- FAQページから用語、用語設定、クラスを設定し、ナレッジグラフをトレーニングして発話を再テストします。
- ナレッジグラフページから選択したFAQに代替の質問として発話を追加し、ナレッジグラフをトレーニングして発話を再テストします。
不適切な一致をマークする
ユーザー入力が誤ったタスクと一致する場合は、次の手順を実行して正しいインテントと一致させます。
- 一致したインテント名の上で、不適切な一致としてマークリンクをクリックします。
- 一致したインテントドロップダウンリストが開き、別のインテントが選択されます。
- ユーザー入力に対応するインテントを選択し、Botをトレーニングします。