
Once you have built and trained your bot, the most important question that arises is how good is your bot’s learning model? So, evaluating your bot’s performance is important to delineate how good your bot understands the user utterances.
The Batch Testing feature helps you discern the ability of your bot to correctly recognize the expected intents and entities from a given set of utterances. This involves the execution of a series of tests to get a detailed statistical analysis and gauge the performance of your bot’s ML model.
To conduct a batch test, you can use predefined test suites available in the builder or create your own custom test suites. Based on your requirement, the test suites can be run to view the desired results. This option can be accessed from the Testing -> Batch Testing option from the left navigation menu.
Managing Test Suites
Kore.ai provides a few out-of-the-box Test Suites to perform batch testing. ‘Developer defined utterances’ and ‘Successful user utterances’ are the built-in test suites that can be run to perform Batch Testing. You can also create a New Test Suite for testing a custom set of utterances.
Developer defined utterances
This test suite validates the utterances that have been previously added and trained by the developer from Machine Learning Utterances screen. Using this test suite would mean testing collectively the entire set of utterances that a developer has added for all tasks of the bot.
Successful user utterances
This test suite includes all the end-user utterances that have successfully matched an intent and the corresponding task is fully executed. You can also find these utterances from the ‘Intent found’ section of the Analyze module.

Adding a New Test Suite
The New Test Suite enables you to import an array of test utterances collectively at once in a batch file, also known as a Dataset. The Dataset file needs to be written in CSV or JSON format and can have a maximum of 10000 utterances. You can download the sample CSV or JSON file formats as part of the test suite creation using the New Test Suite option. The test suite name cannot contain any special characters except underscore (_) and spaces.
JSON Format for Test Suite
The JSON format for creating custom suites allows you to define an array of test cases where each test case should consist of an utterance to be tested, the intent against which the utterance to be tested, and optionally define the list of expected entities to be determined from the utterance. If expected intent is a child intent, then you can also include the parent intent to be considered.

- For Entities that have the Multi-Item enabled, values need to be given as:
entity1||entity2 - Composite Entities require the values in the following format:
component1name:entityValue|component2name:entityValue2

- The order in which the entities are to be extracted can be given as:
"entityOrder":["TransferAmount", "PayeeName"]. If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order.
| Property Name | Type | Description |
|---|---|---|
| Test Cases | Array |
Consists of the following:
|
| input | String | End-use Utterance |
| intent | String |
Determine the objective of an end-user utterance (can be task name or primary question in case of FAQ test case) Post-release 7.3, this property can be used to define traits to be identified against this utterance by using the prefix “trait” for example, Trait: Trait Name1|| Trait Name2||Trait Name3 Post-release 8.0, this property can include the expected Small Talk pattern. |
| botName only for universal bot |
String | Name of the linked bot where the above-mentioned intent belongs |
| parentIntent | String [Optional] | Define parent intent to be considered if the intent is a sub-intent. In the case of Small Talk, this field should be populated when the Small Talk is contextual follow-up intent; in case of multi-level contextual intent the parent intents should be separated by the delimiter || |
| entities | Array [Optional] |
Consists of an array of entities to be determined from the input sentence:
|
| entityValue | String | Value of the entity expected to be determined from the utterance. You can define the expected Entity Value as a string or use a Regular Expression. For the purpose of Batch Testing, the platform flattens all entity values into string formats. Refer Entity Format Conversions for more information. |
| entityName | String | Name of the entity expected to be determined from the utterance |
|
entityOrder (ver7.1 onwards) |
Array [Optional] |
An array of entity names specifying the order in which the entities are to be extracted. If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order. |
CSV Format for Test Suite
CSV format for creating custom suites allows you to define test cases as records in CSV file where each test case should consist of an utterance to be tested, the intent against which the utterance to be tested, and optionally define entities to be determined from the utterance. If your test case requires more than one entity to detected from a sentence, then you have to include an extra row for each of the additional entities to be detected. If expected intent is a child intent, then you can also include the parent intent to be considered.
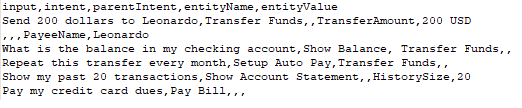
- For Entities that have the Multi-Item enabled values need to be given as:
entity1||entity2 - Composite Entities require the values in the following format:
component1name:entityValue|component2name:entityValue2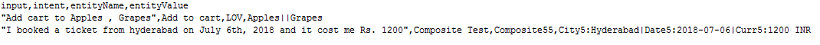
- The order of extraction of entity value can be mentioned in the following format:
entity3>entity4>entity1. If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order.
| Column Name | Type | Description |
|---|---|---|
| input | String | Utterance given by the end-user |
| intent | String |
Determine the objective of an end-user utterance (can be task name or primary question in case of FAQ test case) Post release 7.3, this property can be used to define traits to be identified against this utterance by using the prefix “trait” for example, Trait: Trait Name1|| Trait Name2||Trait Name3 Post-release 8.0, this property can include the expected Small Talk pattern. |
| botName only for universal bot |
String | Name of the linked bot where the above-mentioned intent belongs |
| parentIntent | String [Optional] | Define parent intent to be considered if the intent is a sub-intent In the case of Small Talk, this field should be populated when the Small Talk is contextual follow-up intent and the intent would be matched assuming that the follow-up intent criteria is met; in the case of multi-level contextual intent the parent intents should be separated by the delimiter || |
| entityValue | String [Optional] | Value of the entity expected to be determined from the utterance. You can define the expected Entity Value as a string or use a Regular Expression. For the purpose of Batch Testing, the platform flattens all entity values into string formats. Refer Entity Format Conversions for more information. |
| entityName | String [Optional] | Name of the entity expected to be determined from the utterance |
|
entityOrder (ver7.1 onwards) |
Array [Optional] |
An array of entity names separated by > specifying the order in which the entities are to be extracted. If the order is not provided or partially provided, the platform defines the implicit order to process first the NER and pattern entities and then the remaining entities. |
Entity Format Conversions
| Entity Type | Sample Entity ValueType | Value in Flat Format | Order of Keys |
|---|---|---|---|
| Address | P.O. Box 3700 Eureka, CA 95502 | P.O. Box 3700 Eureka, CA 95502 | |
| Airport | { “IATA”: “IAD”, “AirportName”: “Washington Dulles International Airport”, “City”: “Washington D.C.”, “CityLocal”: “Washington”, “ICAO”: “KIAD”, “Latitude”: “38.94”, “Longitude”: “-77.46” } | Washington Dulles International Airport IAD KIAD 38.94 -77.46 Washington D.C. Washington | AirportName IATA ICAO Latitude Longitude City CityLocal |
| City | Washington | Washington | |
| Country | { “alpha3”: “IND”, “alpha2”: “IN”, “localName”: “India”, “shortName”: “India”, “numericalCode”: 356} | IN IND 356 India India | alpha2 alpha3 numericalCode localName shortName |
| Company or Organization Name | Kore.ai | Kore.ai | |
| Color | Blue | Blue | |
| Currency | [{ “code”: “USD”, “amount”: 10 }] | 10 USD | amount code |
| Date | 2018-10-25 | 2018-10-25 | |
| Date Period | { “fromDate”: “2018-11-01”, “toDate”: “2018-11-30” } | 2018-11-01 2018-11-30 | fromDate toDate |
| Date Time | 2018-10-24T13:03:03+05:30 | 2018-10-24T13:03:03+05:30 | |
| Description | Sample Description | Sample Description | |
| user1@emaildomain.com | user1@emaildomain.com | ||
| List of Items(Enumerated) | Apple | Apple | |
| List of Items(Lookup) | Apple | Apple | |
| Location | { “formatted_address”: “8529 Southpark Cir #100, Orlando, FL 32819, USA”, “lat”: 28.439148,”lng”: -81.423733 } | 8529 Southpark Cir #100, Orlando, FL 32819, USA 28.439148 -81.423733 | formatted_address lat lng |
| Number | 100 | 100 | |
| Person Name | Peter Pan | Peter Pan | |
| Percentage | 0.25 | 0.25 | |
| Phone Number | +914042528888 | +914042528888 | |
| Quantity | { “unit”: “meter”, “amount”: 16093.4, “type”: “length”, “source”: “10 miles” } | 16093.4 meter length 10 miles | amount unit type source |
| String | Sample String | Sample String | |
| Time | T13:15:55+05:30 | T13:15:55+05:30 | |
| Time Zone | -04:00 | -04:00 | |
| URL | https://kore.ai | https://kore.ai | |
| Zip Code | 32819 | 32819 |
Importing a Dataset file
- Click New Test Suite on the batch testing page. A dialog box to import the dataset appears.
- Enter a Name, Description, and choose a Dataset Type in the respective boxes for your dataset file.
- To import the Dataset file, click Choose File to locate and select a JSON or CSV file containing the utterances as per the Dataset Type selected.
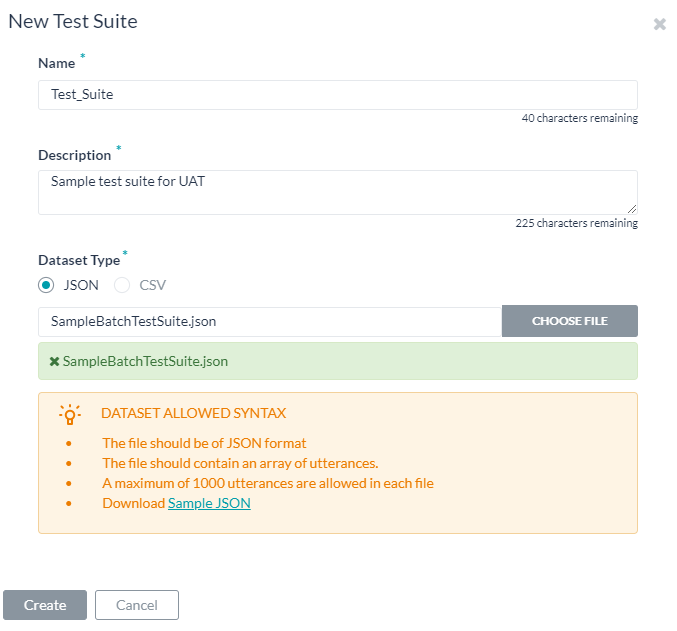
- Click Create. The dataset file will appear as an option to run the test suite on the batch testing page:

Running Test Suites
The following steps will guide you on how to run a batch test on your bot and obtain a detailed analytical report on the utterances based on the test results. To get started, click Batch Testing in the Testing section on the builder.
To run a Test Suite, for example, the Developer Defined utterances, click Developer Defined Utterances followed by Run Test Suite. This will initiate the batch test for Developer defined utterances. Post-release of ver7.3, you can run the test suite against the in-development or published version of the bot.
The test will display the results as explained below. Each test run will create a test report record and displays a summary of the test result. The batch test result in the screenshot below includes the following information:
- Last Run Date & Time that displays the date and time of the latest test run.
- F1 Score is the weighted average of Precision and Recall.
- Precision is the number of correctly classified utterances divided by the total number of utterances that got classified (correctly or incorrectly) to an existing task ie the ratio of true positives to all classified positives (sum of true and false positives).
- Recall is the number of correctly classified utterances divided by the total number of utterances that got classified correctly to any existing task or classified incorrectly as an absence of an existing task ie the ratio of correctly classified utterances to actual matching intents/tasks (sum of true positives and false negatives)..
- Intent Success % that displays the percentage of correct intent recognition that has resulted from the test.
- Entity Success % that displays the percentage of correct entities recognition that has resulted from the test.
- Version Type identifies the version of the bot against which the test suite was run – development or published.
- There are three possible outcomes from each test run:
- Success – when all records are present in the file are processed
- Success with a warning – when one or more records present in the suite are discarded from detection due to system error
- Failed – when there was a system error and the test could not be resumed post-recovery.
Hovering over the warning/error icon will display a message suggesting the reason.
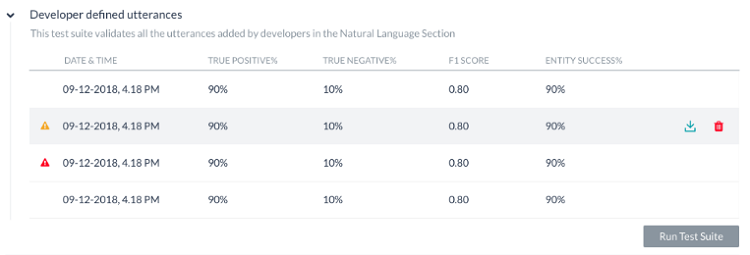
To get a detailed analysis of the test run, click the Download icon to download the test report in CSV format. You have an option to delete the test results if needed. The top section of the report comprises the summary with the following fields:
- Bot Name
- Report name of the test suite
- Bot Language (post 7.3 release)
- Run Type identifies the version of the bot against which the test suite was run – development or published.
- Threshold Setting (post 7.3 release) detailing the NLP thresholds applied when running this test suite, this would be followed by the settings for each of the three NL engines with the following details:
- Mode – ml, faq, or, cs
- minThreshold
- maxThreshold
- exactMatchThreshold
- isActive
- taskMatchTolerance
- wordCoverage
- suggestionsCount
- pathCoverage
- Last Tested: Date of the latest test run for developer-defined utterances.
- Utterance Count: Total number of utterances included in the test run.
- Success/Failure Ratio: Total number of successfully predicted utterances divided by the total count of utterances multiplied by 100.
- True Positive (TP): Percentage of utterances that have correctly matched expected intent. In the case of Small Talk, it would be when the list of expected and actual intents are the same.
- True Negative (TN): Percentage of utterances that were not expected to match any intent and they did not match. Not applicable to Small Talk.
- False Positive (FP): Percentage of utterances that have matched an unexpected intent. In the case of Small Talk, it would be when the list of expected and actual intents are different.
- False Negative (FN): Percentage of utterances that have not matched expected intent. In the case of Small Talk, it would be when the list of expected Small Talk intent is blank and but the actual Small Talk is mapped to an intent.

The report also provides detailed information on each of the test utterances and the corresponding results.
- Utterances – Utterances used in the corresponding test suite.
- Expected Intent – The intent expected to match for a given utterance, will include trait where applicable with trait prefix
- Matched Intent – The intent that is matched for an utterance during the batch test. This will include matched traits (post 7.3 release). This will include matched Small Talk intents (post 8.0 release).
In case of Universal Bot, for FP result this will contain the linked bot: matched intent. - Parent Intent – The parent intent considered for matching an utterance against an intent.
- Task State – The status of the intent or task against which the intent is identified. Possible values include Configured or Published
- Result Type – Result categorized as True Positive or True Negative or False Positive or False Negative
- BotName: For universal bot the name of the linked bot as given in the test suite
- Entity Name – The name of the entity detected from the utterance.
- Expected EntityValue – The entity value expected to be determined during the batch test.
- Matched EntityValue – The entity value identified from an utterance.
- Entity Result – Result categorized as True or False to indicate whether the expected entity value is the same as the actual entity value.
- Expected Entity Order – entity values from the input file
- Actual Entity Order –
- if the order for all expected entities is provided, then the same is included in this column
- if no order is provided, the system determined order will be included in the column
- If an order is provided for some entities, then a combination of user-defined order and system-defined order will be included
- Matched Intent’s Score – For False Positives and False Negatives, the confidence scores from FM, ML, and/or KG engines are displayed for the matched intent from the utterance. Note that the scores are given only if the engine detects the intent, that means that you may not see the scores from all the three engines at all times.
- Expected Intent’s Score – For False Positives, the confidence scores for the intent expected to match for the given utterance is given. Again the score will be given by the engines detecting the intent.
Important Notes:
- An optimal approach to bot NLP training is to first create a test suite of most of the use cases(user utterances) that the bot needs to identify, run it against the model and start training for the ones that failed.
- Create/update batch testing modules for high usage utterances.
- Publish the trained model only after detailed testing.
- When naming the intent, ensure that the name is relatively short (3-5 words) and does not have special characters or words from the Stop Wordlist. Try to ensure the intent name is close to what the users request in their utterance.
- Batch Test executions do not consider the context of the user. Hence you might see some False Negatives in the test results which in fact are True Positives in the actual bot when the context is taken into consideration.