
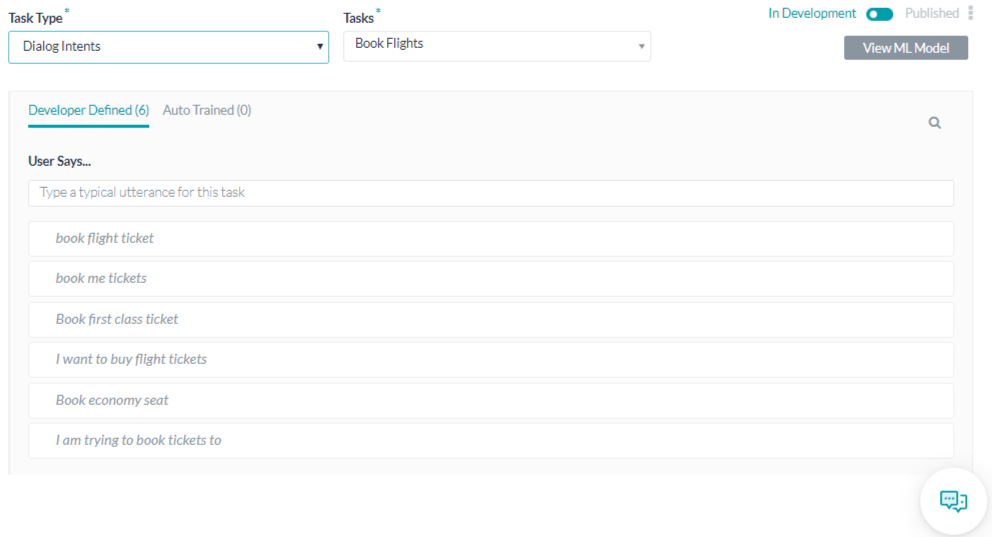
Developers need to provide sample utterances for each intent (task) the bot needs to identify to train the machine learning model. The platform ML engine will build a model that will try to map a user utterance to one of the bot intents.
Kore.ai’s Bots Platform allows fully unsupervised machine learning to constantly expand the language capabilities of your chatbot – without human intervention. Unlike unsupervised models in which chatbots learn from any input – good or bad – the Kore.ai Bots Platform enables chatbots to automatically increase their vocabulary only when the chatbot successfully recognizes the intent and extracts the entities of a human’s request to complete a task.
However, we recommend keeping Supervised learning enabled to monitor the bot performance and manually tune where required. Using the bots platform, developers can evaluate all interaction logs, easily change NL settings for failed scenarios, and use the learnings to retrain the bot for better conversations.
Adding Machine Learning Utterances
- Open the bot for which you want to add sample user utterances.
- Hover over the side navigation panel and then click Natural Language -> Training.
- Select the Machine Learning Utterances tab.
The negation of trained intents will be ignored by the platform.
For example, consider a Banking Bot with trained utterance – Funds Transfer. Then a user utterance “My account is debited even without doing funds transfer” will not trigger the “funds transfer” task.
Named Entity Recognition
Apart from the intent, you can train your Bot to recognize the entities, if present, in the user utterance. For example, if the user says “Book Flight from Hyderabad to Mumbai” apart from recognizing the intent as “Book Flight” the source and destination of the flight should also be recognized. This can be achieved by marking the entities in the user utterance during training.
You can mark entities in your utterances, by selecting the entity value and clicking the corresponding entity from the drop-down list.
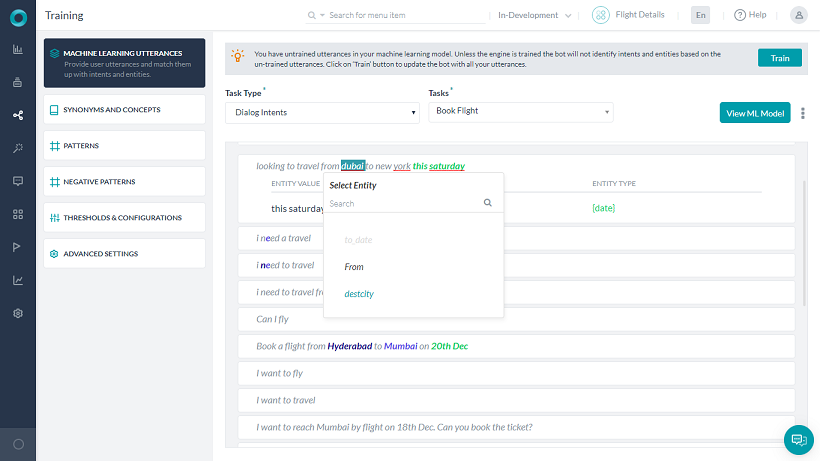
The platform will also try to identify and mark the entities, you have the option to accept or discard these suggestions. The platform will identify the entities based upon:
- System entities;
- Static List of items either enumerated or lookup;
- NER trained entities (from above).
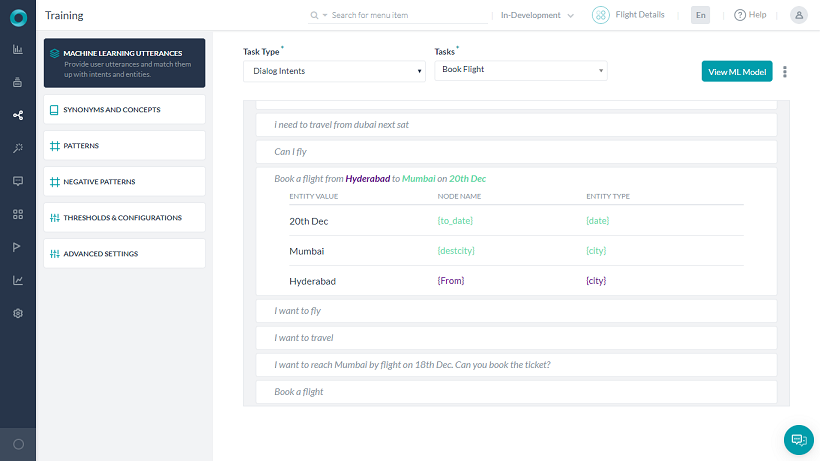
Further, if you have enabled Entity Placeholders the platform will replace the entity values in the training utterance with entity name placeholders for training the ML model. Using actual entity values as well as multiple additions of an utterance with just change in the entity value will have an adverse impact on the ML training model. Name of entities also starts contributing highly to the intent detection model.
Training your Bot
After you add user utterances, you should train the Kore.ai interpreter to recognize the utterances and the associated user intent. When you have untrained utterances in your bot, the following message is displayed:
“You have untrained utterances in your machine learning model. Unless the engine is trained the bot will not identify intents and entities based on the un-trained utterances. Click on ‘Train’ button to update the bot with all your utterances.”
In the User Says section, click Train. A status bar is displayed to show progress for utterance training. When complete, the Utterances trained successfully message is displayed. The user utterances are added to the Machine Learning database.
Learn how to test your bot.
Auto-Train
By default, machine learning is automatically trained for any defined user utterances whenever a task is:
- changed from a status of In-Progress to Configured.
- updated with a new
- task name or intent name,
- entity name or parameter name,
- entity type,
- bot name.
- published.
- suspended by the Bots Admin.
- deleted by the Bots Admin.
In Bot Builder when auto-train is in progress, a warning message that untrained user utterances cannot be identified is displayed if you try to test the bot before auto-train is complete.
You can set the Auto Train option as follows:
- Open the bot for which you want to modify the settings.
- Hover over the side navigation panel and then click Natural Language -> Training.
- Select the Advanced Settings tab.
- Enable or Disable the Auto Training option as per your requirements.
Negative Patterns
Negative patterns can be used to eliminate intents detected by the Fundamental Meaning or Machine Learning models. Refer here to know more.
Threshold & Configurations
To train and improve the performance Threshold and Configurations can be specified for all three NLP engines – FM, KG and ML. You can access these settings under Natural Language > Training > Thresholds & Configurations.
NOTE: If your Bot is multilingual, you can set the Thresholds differently for different languages. If not set, the Default Settings will be used for all languages.
The settings for ML engine is discussed in detail in the following sections.
Machine Learning
The Bots Platform ver 6.3 upgraded its Machine Learning (ML) model to v3. This includes a host of improvements and also allows developers to fine tune the model using parameters to suit business requirement. The developers can change parameters like stopword usage, synonym usage, thresholds, and n-grams, as well as opt between Deep Neural Network or Conditional Random Field-based algorithm for the Named-Entity Recognition (NER) model.
Configuring the Machine Learning Parameters
The Bots Platform provides language-wise defaults for the following parameters related to the ML performance of your bot. You can customize them to suit your particular needs.
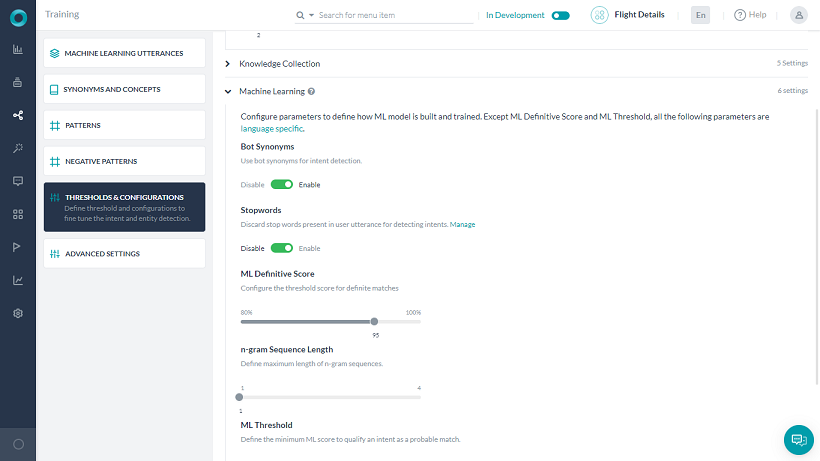
Bot Synonyms
This setting is Disabled by default. Enable this option if you would like to consider intent synonyms in building the ML model.
Stop Words
This setting is Disabled by default. Enable this option if you would like to remove the stop words in the training utterances in building the ML model.
ML Definitive Score
Configure the threshold score for definite matches, can be set to a value between 80-100%.
n-gram Sequence Length
n-gram is the contiguous sequence of words to be used from training sentences to train the model. For example, if Generate sales forecast report is the user utterance and if n-gram is set to 2, then Generate sales, Sales forecast, and Forecast report are used in training the model.
The minimum n-gram limit is 1 by default. You can set the maximum limit up to 4.
ML Threshold
Define the minimum ML score to qualify an intent as a probable match. Learn more about ML Scoring.
NER Model
Choose the NER model to be used for entity detection.
Entity Placeholders
Enable to replace entity values present in the training utterances with the corresponding entity placeholders in the training model.
Upgrading the ML Model
All new bots that are created use the new ML model by default. Developers can upgrade the ML model for old bots or downgrade the model for the bots using the new model.
If you are using a previous model of ML in the bots platform, you can upgrade it as follows:
- Open the bot for which you want to upgrade the ML model and go to Natural Language > Advanced Settings.
- Expand Machine Learning. Under ML Upgrade section, click the Upgrade Now button. It opens a confirmation window.
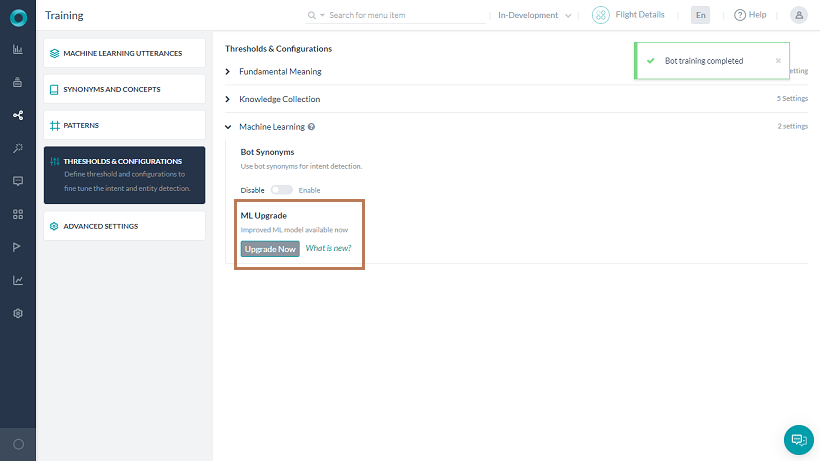
- Click Upgrade and Train. You can see new customizable options under the Machine Learning section.
You can also downgrade the ML model for new or upgraded bots from here by clicking Switch to older version. However, note that the older version of the ML model will be deprecated soon. So, we strongly recommend staying on the latest version to receive continued support and future enhancements.
Note: If a bot is exported using the older model (V2) and imported as a new bot, it continues to be in V2 model until you upgrade it.
Exporting and Importing Machine Learning Utterances
You can import and export ML utterances of a bot into another in CSV and JSON formats. You can choose between ‘In-Development’ or ‘Published’ tasks to export, whereas importing utterances always replace the latest copy of the task in the bot.
How to Export or Import ML Utterances
- On the bot’s menu, click Natural Language > Machine Learning Utterances.
- The ‘In-Development’ version of the bot’s ML utterances open by default. If you want to see the utterances in the ‘Published’ version, toggle on the top right side of the window to Published.
Note: The export of ML utterances vary based on this selection as explained in the Versioning and Behavior of the Exported UUtterances section below.
- Click the options icon and select an option:
- Click Import and upload a CSV or JSON file with the utterances to import. Read Versioning and Behavior of the Imported Utterances section below for more information.-OR-
- Click Export and select CSV or JSON formats to export the utterances. Read Versioning and Behavior or the Exported Utterances section below for more information.
Versioning and Behavior of Imported Utterances
- The imported utterances in CSV/JSON entirely replace the utterances present in the latest copy of the tasks.
- If the task is in the Configured status, the utterances in the task get entirely replaced with the new utterances for the task present in the imported file.
- If the task is in Upgrade in Progress status, the utterances related to the task get entirely replaced with the task utterances present in the imported file. The utterances in the Published copy of the task aren’t affected.
- If the task is in the Published status, an Upgrade in Progress copy of the task gets created by default and the new utterances present in the imported file will be added to the upgraded copy. The utterances in the Published copy of the task aren’t affected.
Versioning and Behavior of Exported Utterances
- When you export a bot’s utterances, all the utterances related to every task type – alert, action, information, dialog – get exported.
- When you export an In Development copy of the bot, the utterances of all tasks in the latest available copy get exported.
- When you export a Published copy of the bot, all the utterances in the published state get exported.
- In the case of multi-language bots, the export of utterances only happens for the selected bot language.
- Export of utterances to JSON include NER tagging present in the tasks, whereas CSV export doesn’t include them.
ML Training Recommendations
- Give a balanced training for all the intents that the bot needs to detect, add approximately the same number of sample utterances. A skewed model may result in skewed results.
- Provide at least 8-10 sample utterances against each intent. The model with just 1-2 utterances will not yield any machine learning benefits. Ensure that the utterances are varied and you do not provide variations that use the same words in a different order.
- Avoid training common phrases that could be applied to every intent, for example, “I want to”. Ensure that the utterances are varied for larger variety and learning.
- After every change, train the model and check the model. Ensure that all the dots in the ML model are diagonal (in the True-positive and True-negative) quadrant and you do not have scattered utterances in other quadrants. Train the model until you achieve this.
- Regularly train the bot with new utterances.
- Regularly review the failed or abandoned utterances and add them to utterance list against a valid task or intent.
NLP Intent Detection Training Recommendations
- If there are a good number of sample utterances, try training the bot using Machine Learning approach first, before trying to train the fundamental meaning model.
- Define bot synonyms to build a domain dictionary such as pwd for a password; SB for a savings bank account.
- After every change to the model training, run the batch testing modules. Test suites are a means to perform regression testing of your bot’s ML model.
NLP Entity Detection Training Recommendations
The best approach to train entities is based on the type of entity as explained below:
- Entity type like List of Items (enumerated, lookup), City, Date, Country do not need any training unless the same entity type is used multiple types in the same task. If the same entity type is used in a bot task, use either of the training models to find the entity within the user utterances.
- When the entity type is String or Description, the recommended approach is to use Entity patterns and synonyms.
- For all other entity types, both NER and Patterns can be used in combination.
Entity Training Recommendations
- Use NER training where possible – NER coverage is higher than patterns.
- NER approach best suits detecting an entity where information is provided as unformatted data. For entities like Date and Time, the platform has been trained with a large set of data.
- NER is a neural network-based model and will need to be trained with at least 8-10 samples to work effectively.