
Kore.ai’s Knowledge Graph helps you turn your static FAQ text into an intelligent, personalized conversational experience. It goes beyond the usual practice of capturing FAQs in the form of flat question-answer pairs. Instead, Knowledge Graph enables you to create an ontological structure of key domain terms and associate them with context-specific questions and their alternatives, synonyms, and Machine learning-enabled traits. This Graph, when trained by the platform, enables an intelligent FAQ experience.
This document talks of the concepts, terminology and implementation of Knowledge Graph. For a use case driven approach to Knowledge Graph, refer here.
Why Knowledge Graph
Any query can be expressed in multiple ways by the user. It is a difficult task for you to visualize and add all the alternative questions manually.
Kore.ai designed Knowledge Graph with nodes, tags, and synonyms which would make the work easier for you to cover all the possible matches. The Knowledge Graph can handle various alternate questions with the training using the nodes, tags, and synonyms.
Whenever a question is asked by the user the node names in the Knowledge Graph will be checked and matched with the keywords from the question. Node names, tags, and synonyms will be checked and based on the score, the best possible intent will be presented to the user which can take the form of either a simple response or execution of a dialog task.
This way, you can add a very few completely different alternative questions in the FAQ and provide tags, synonyms and node names appropriately such that any untrained question can also be matched. The performance and intelligence of the Knowledge Graph depend on the way you train it with the appropriate node names, tags, and synonyms.
Terminology
This document is intended to familiarize the reader with the terms used in building Knowledge Graph.
Terms or Nodes
Terms or Nodes are the building blocks of an ontology and they can be used to define the fundamental concepts and categories of a business domain.
As shown in the image below, you can organize the terms on the left-hand panel of the Bot Ontology window in a hierarchical order to represent the flow of information in your organization. You can create, organize, edit, and delete terms from there.
For easier representation, we identify some special nodes using the following names:
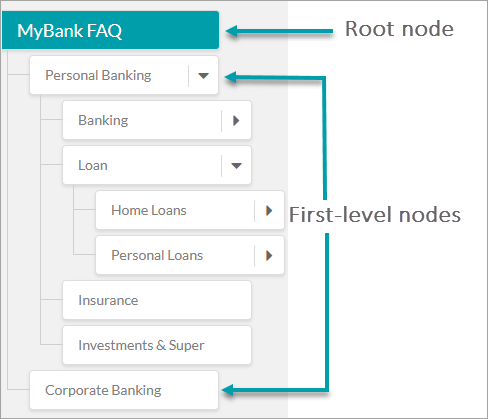
Root Node
Root node forms the topmost term of your Bot Ontology. A Knowledge Graph consists of only one root node and all other nodes in the ontology become its child nodes. Root node takes the name of the bot by default, but you can change it if you want. This node is not used for node qualification or processing. The path qualification starts from first level nodes.
First-level Nodes
The immediate next level nodes of the root node are known as First-level nodes. There can be any number of First-level nodes in a collection. It is recommended to keep First-level nodes to represent high-level terms such as the names of departments or functionality. Examples – Personal Banking, Online Banking, and Corporate Banking.
Leaf Node
Any node to which question-answer set or dialog task is added is called a Leaf Node, be it at any level.
Node Relation
Depending on their position in the ontology, a node can be referred to as first-level nodes, second-level nodes, etc.. A first-level node is in simple terms a category that may have one or more subcategories under it, called the second-level nodes.
Examples: Loan is the first-level node of Home Loan and Personal Loan. Personal Loan can again have two subcategory nodes: Rate and Fees, Help and Support.
Tags
Synonyms
Users would use a variety of alternatives for the terms of your ontology. Knowledge Graph allows you to add synonyms for the terms to include all possible alternative forms of the terms. Adding synonyms also reduces the need for training the bot with alternative questions.
For example, the Internet Banking node may have the following synonyms added to it: Online Banking, e-banking, E-banking, Cyberbanking, and Web banking.
When you add a synonym for a term in the Knowledge Graph, you can add them as local or global synonyms. Local synonyms apply to the term only in that particular path, whereas global synonyms apply to the term even if it appears on any other path in the ontology.
Traits
Note: From ver 7.0, Traits replace Classes of ver 6.4 and before.
A trait is a collection of typical end-user utterances that define the nature of a question when they ask for information related to a particular intent. See here for more on traits.
A trait can be applied to multiple terms across your Bot Ontology.
Intent
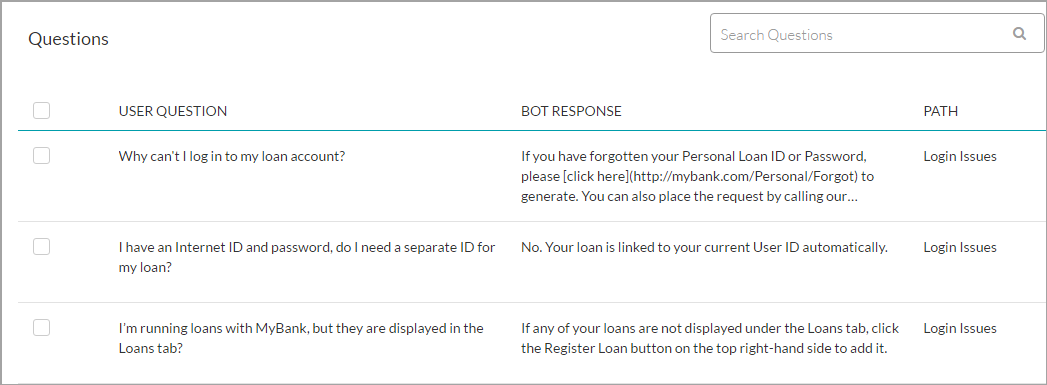
A question may be asked differently by different users and to support this, you may associate multiple alternate forms for each question.
Bot can respond to a given question from the user either with an execution of a Dialog Task or an FAQ.
- FAQ: The question-answer pairs must be added to relevant nodes in your bot ontology.
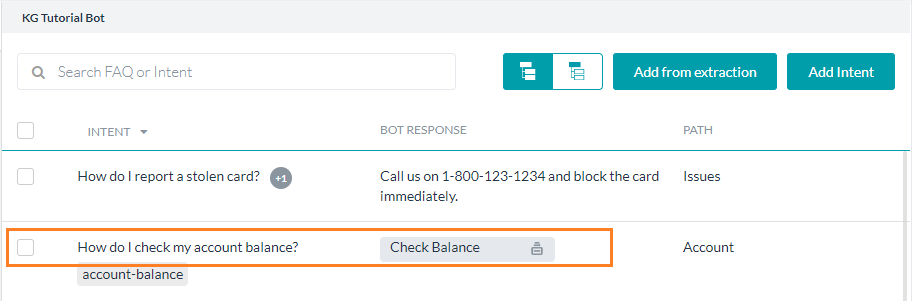
- Task: Linking a Dialog task to a KG Intent helps to leverage the capabilities of the Knowledge Graph and Dialog tasks to handle FAQs that involve complex conversations.
Improving Performance
Though Knowledge Graph engine works well with the default settings, you, as a Bot developer, can fine-tune the KG engine performance in many ways:
- Configure Knowledge Graph properly by defining terms, synonyms, primary and alternative questions or user utterances. Though hierarchy does not affect the KG engine performance, it does help in organizing and guiding the working of the KG engine.
- Setting the following parameters:
- Path Coverage – Define the minimum percentage of terms in the user’s utterance to be present in a path to qualify it for further scoring.
- Definite Score for KG – Define minimum score for a KG intent match to be considered as a definite match and discard any other intent matches found.
- Minimum and Definitive Level for Knowledge Tasks – Define minimum and definitive threshold to identify and respond in case of a Knowledge task.
- KG Suggestions Count – Define the maximum number of KG / FAQ suggestions to be presented when a definite KG intent match is not available.
- The proximity of Suggested Matches – Define the maximum difference to be allowed between top-scoring and immediate next suggested questions to consider them as equally important.
While the platform provides default values for the above-mentioned thresholds, these can be customized from the Natural Language -> Training -> Thresholds & Configurations.
- Qualify Contextual Paths – This will ensure that the Bot context is populated and retained with the terms/nodes of the matched intent. This will further smooth the user experience.
- Traits – As mentioned earlier, traits can be used to qualify a nodes/terms even if the user utterance does not contain the term/node. Traits are also helpful in filtering the suggested intent list.
Working of KG Engine
Knowledge Graph engine uses a two-step approach while extracting the right response to the user utterance. It combines a search-driven intent detection process with rule-based filtering. The settings for path coverage (percentage of terms needed) and term usage (mandatory or optional) in user utterance helps in the initial filtering of the FAQ intents. Tokenization and n-gram based cosine scoring model aids in the fulfillment of the final search criteria.
Training of the Knowledge Graph involves the following steps:
- All the terms/nodes along with synonyms are identified and indexed
- Using these indices, a flattened path is established for each KG Intent.
Once the Knowledge Graph Engine receives a user utterance:
- The user utterance and KG nodes/terms are tokenized and n-gram is extracted (a max of quad-gram is supported by Knowledge Graph Engine)
- The tokens are mapped with the KG nodes/terms to obtain their respective indices
- Path comparison between the user utterance and KG nodes/terms establishes the qualified path for that utterance. This step takes into consideration the path coverage and term usage mentioned above.
- From the list of questions in the qualified path, the best match is picked based upon cosine scoring.