開発者は、機械学習モデルをトレーニングするためにBotによる識別を必要とするそれぞれのインテント(タスク)に対して、サンプルの発話を提供する必要があります。プラットフォームのMLエンジンは、Botのインテントの1つにユーザーの発話をマッピングしようとするモデルを構築します。
Kore.aiのBotプラットフォームは、完全に教師なしの機械学習によって、人間が介入することなく継続的にチャットBotの言語能力を拡張することができます。Kore.aiのBotプラットフォームでは、チャットBotがあらゆる入力(善悪を問わず)から学習する教師なしモデルとは異なり、チャットBotが正常にインテントを認識し、人間がタスクを完了させるために要求した内容を抽出した場合にのみ、チャットBotは自動的に語彙を増やすことができます。
ただし、Botのパフォーマンスを監視し、必要に応じて手動で調整を行えるよう、教師あり学習を有効にしておくことをお勧めします。Botプラットフォームを使用することで、開発者はすべての対話ログを評価し、失敗したシナリオのNL設定を簡単に変更し、会話の精度を上げるために学習を使用してBotを再度トレーニングすることができます。
複数インテント モデル
(v8.1で導入) 目的が異なる「類似インテント」のトレーニングは、多くの場合難しいものです。一つのインテントに与えられるトレーニングが、ノイズや他のインテントのトレーニングとの矛盾を含む場合があるからです。 これは、インテントが文脈上異なる意味や目的を持っている場合にはより顕著になります。
次のようなケースを考えてみましょう。ユーザーが注文タスクにいるときの返品条件や配送オプションに関する問い合わせは、注文コンテキスト内で回答されなければなりません。 ところが、一般的な商品返品の FAQ の質問がトリガーされてしまいます。

詳細 NLP 設定 (設定方法についてはこちらをご覧ください) で複数インテント モデルを有効にすると、プライマリ インテント専用の機械学習モデルを作成して、サブインテントのインテント検出が優先されるよう、関連サブインテントを持つダイアログごとに機械学習モデルを分けることができます。
上記の例では、複数インテント モデルを使用してコンテキスト ベースの FAQ を個別に定義し、ユーザーに適切な応答を返すことができます。

ボットのすべてのプライマリ インテントは、ボット レベルのインテント モデルの一部となります。 それぞれのダイアログ タスクは、追加されたすべてのサブインテントからなる独自の機械学習モデルを持ちます。しきい値および設定は、モデルごとに個別に設定できます。
たとえば、ボット レベルのインテント モデルは「標準」ネットワーク タイプを、特定のダイアログのインテント モデルは「LSTM」ネットワーク タイプを使用することができます。

機械学習の発話の追加
体験向上のために、プラットフォームのバージョン8.1ではUIが再設計されています。
- サンプルのユーザー発言を追加するBotを開きます。
- 左ペインから、自然言語 > トレーニングをクリックします。
- 機械学習の発話タブを選択します。
- すべてのインテント一覧が提供され、フィルタオプションを使用して表示項目をダイアログ、サブダイアログ、サブインテントに制限することができます。

- 発話を追加するインテントを選択すると、ユーザーの発話ページが開きます。

- こちらに発話を入力します。
プラットフォームは、トレーニングされたインテントのネゲーションを無視します。
例えば、「Funds Transfer」というトレーニングされた発話を含むバンキングBotを例に考えてみましょう。その場合、「My account is debited even without doing funds transfer」というユーザーの発言は、「funds transfer」タスクのトリガーにはなりません。
名前付きエンティティの認識
インテントとは別に、ユーザーの発話の中にエンティティが存在する場合には、それを認識するようBotをトレーニングすることができます。例えば、ユーザーが「Book Flight from Hyderabad to Mumbai」と言った場合、「Book Flight」というインテントを認識するだけでなく、フライトの出発地と目的地も認識する必要があります。これは、ユーザーの発話内のエンティティをトレーニング中にマークすることで行われます。
エンティティ値を選択し、ドロップダウンリストから対応するエンティティをクリックすることで、発話の中にエンティティをマークすることができます。

さらに、プラットフォームはエンティティを識別してマークを付けようとしますが、お客様はこれらの提案を受け入れるか破棄するかを選択することができます。プラットフォームは、以下に基づいてエンティティを識別します。
- システムエンティティ
- 列挙またはルックアップのいずれかの項目の静的リスト
- NERのトレーニング済みエンティティ(上から)
このようにしてマークされたそれぞれのエンティティについて、MLエンジンによって識別された信頼度スコアが表示されます。これはプラットフォームのリリース8.0で導入されたもので、NERモデルとして条件付きランダムフィールドが選択されている場合にのみ利用可能です。

さらに、エンティティプレースホルダを有効にしている場合、トレーニング用の発話のエンティティ値をエンティティ名プレースホルダに置き換えてMLモデルをトレーニングします。エンティティ値を変更しただけの発話を複数回追加した場合と同様に、実際のエンティティ値を使用すると、MLのトレーニングモデルに悪影響を与えます。また、エンティティ名もインテント検出モデルに大きな影響を与えます。
Botのトレーニング
ユーザーの発言を追加した後、Kore.aiインタプリタをトレーニングして発話と関連するユーザーインテントを認識させる必要があります。Botにトレーニングされていないの発話がある場合、以下のようなメッセージが表示されます。
「機械学習モデルにはトレーニングされていない発話があります。エンジンがトレーニングされない限り、トレーニングされていない発話に基づき、Botはインテントおよびエンティティを識別しません。すべての発話でBotを更新するには、[トレーニング]ボタンをクリックしてください。」
ユーザーの言葉セクションのトレーニングをクリックします。発話トレーニングの進捗状況を示すステータスバーが表示されます。完了すると、発話は正常にトレーニングされましたというメッセージが表示されます。ユーザーの発話が機械学習データベースに追加されます。さらに、MLエンジン(リリース8.0以降)を設定したり、ユーザーの発話にBotのトレーニングで使用されていない単語、つまりBotの語彙が含まれている場合にダミーのインテントを識別したりすることができます。詳細についてはこちらを参照してください。
自動トレーニング
デフォルトでは、タスクが以下の場合に、定義済みのユーザーの発話に対して機械学習が自動的にトレーニングされます。
- 進行中 から 設定済み に変更された。
- 以下の項目が更新された。
- タスク名またはインテント名
- エンティティ名またはパラメータ名
- エンティティタイプ
- Bot名
- 公開された。
- Bot管理者によって一時停止された。
- Bot管理者によって削除された。
自動トレーニング中のBotビルダーでは、自動トレーニングが完了する前にBotのテストを実行しようとした場合、トレーニングされていないユーザーの発話を識別することはできませんという警告メッセージが表示されます。
自動トレーニングオプションは以下のように設定することができます。
- 設定を変更するBotを開きます。
- サイドナビゲーションパネルにカーソルを合わせ、自然言語 > トレーニングをクリックします。
- 詳細設定タブを選択します。
- 要件に応じて自動トレーニングオプションを有効または無効にします。
ネガティブパターンs
ネガティブパターンは、ファンダメンタルミーニングや機械学習モデルによって検出されたインテントを排除するために使用することができます。詳細はこちらを参照してください。[/vc_column_text][us_separator size="small" show_line="1"][vc_column_text]
しきい値および設定
ファンダメンタル ミーニング、ナレッジ グラフ、機械学習の 3 つの NLP エンジンにしきい値および設定を指定して、トレーニングとパフォーマンスの向上を図ることができます。 これらは [自然言語] > [トレーニング] > [しきい値および設定] で設定できます。
メモ:: ボットが多言語に対応している場合は、言語ごとにしきい値を設定することができます。 設定しない場合は、すべての言語にデフォルトの設定が適用されます。
機械学習エンジンの設定については、以下のセクションで詳しく解説しています。
機械学習
ボット プラットフォーム バージョン 6.3 では、機械学習モデルが v3 にアップグレードされています。 これには改良点が多数含まれており、開発者はパラメーターを使用して、ビジネス要件に合わせてモデルを微調整することができます。開発者はストップ ワードや同義語の使用、しきい値、N グラムのパラメーターを変更したり、固有表現認識 (NER) モデルにディープ ニューラル ネットワークまたは条件付きランダム フィールド ベースのアルゴリズムを選択したりすることができます。
プラットフォームの v8.0 では、機械学習インテント モデルの v5 を使用して、いくつかのハイパーパラメーターを外部化できるようになりました。 これは詳細 NLP 設定で実現できます。詳細については、こちらを参照してください.
プラットフォームの v8.1 では、複数インテント モデル機能が導入されました。 「複数インテント モデル」オプションが有効になっている場合、機械学習エンジンはボットの複数インテント モデルを次のように管理します。
- プライマリ ダイアログ インテントや通知タスク インテントなどのボットのすべてのプライマリ インテントを含む、ボット レベルのインテント モデルです。
- ダイアログ インテント モデル – ダイアログの定義に追加されたサブインテント ノード、グループ ノードの一部としてスコーピングされたサブインテント、ダイアログの定義に追加された割り込みの例外を含む、すべてのプライマリ ダイアログ インテントとサブダイアログ インテントに一つずつ指定します。
しきい値および設定で、インテント モデルごとに個別に設定できます。 これは、以下を含みます。
- しきい値および設定以下の設定 – 次のセクションで解説されている機械学習エンジン
- こちらで詳しく説明されている、詳細 NLP エンジン設定以下のすべての機械学習エンジン設定 .
しきい値と設定
トレーニングを行い、パフォーマンスを向上させるために、FM、KG、MLの3つのNLPエンジンすべてに対して、しきい値と設定値を指定することができます。これらの設定は、自然言語 > トレーニング > しきい値と設定からアクセスすることができます。
注:Botが多言語の場合、言語ごとに異なるしきい値を設定することができます。設定されていない場合、すべての言語でデフォルト設定が使用されます。
MLエンジンの設定については、以下のセクションで詳述します。
機械学習
Botプラットフォームのバージョン6.3では、機械学習(ML)モデルがバージョン3にアップグレードされました。これには多くの改善点が含まれており、開発者はビジネス要件に合わせてパラメータを使用してモデルを微調整することができるようになりました。開発者は、ストップワードの使用、同義語の使用、しきい値、n-gramsなどのパラメータを変更できるだけでなく、名前付きエンティティ認識(NER)モデルの深層ニューラルネットワークまたは条件付きランダムフィールドベースのアルゴリズムを選択することができます。
プラットフォームのバージョン8.0では、MLインテントモデルのバージョン5を使用し、いくつかのハイパーパラメータを外部化するためのプロビジョニングが有効になっています。これは、NLPの詳細設定から行えます。
機械学習パラメータの設定
Botプラットフォームは、お客様のBotのMLパフォーマンスに関連する以下のパラメータの、言語ごとのデフォルト値を適用します。特定のニーズに合わせてカスタマイズすることが可能です。
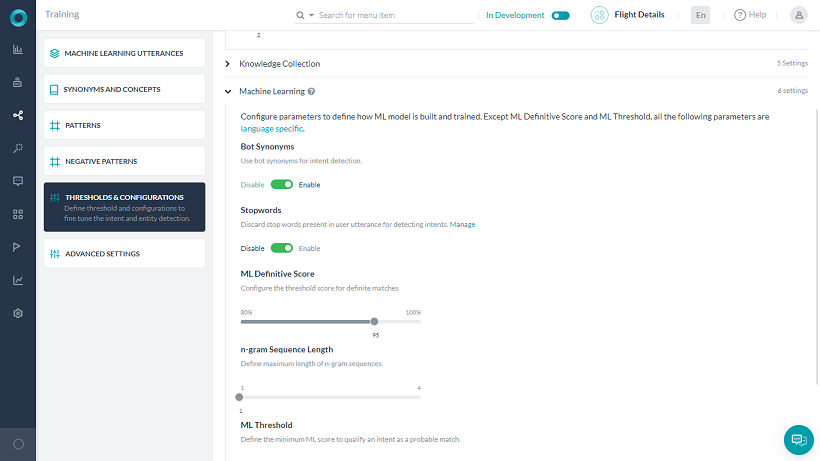
Botの同義語
デフォルトではこの設定は無効になっています。MLモデルを構築する際にインテントの同義語を考慮したい場合には、このオプションを有効にしてください.
ストップワード
デフォルトではこの設定は無効になっています。MLモデルを構築する際にトレーニングしている発話内のストップワードを削除したい場合は、このオプションを有効にしてください。
ML確定スコア
完全一致のしきい値スコアを設定します。80〜100%の値に設定できます。
特徴抽出
このオプション(バージョン8.0で導入)を使用すると、MLインテントモデルを優先するアルゴリズムと関連付けることができます。
- n-gram – これはデフォルトの設定であり、モデルをトレーニングするためにトレーニング文から使用される単語の連続シーケンスを定義するために使用することができます。
例えば、ユーザ発話がGenerate sales forecast reportで、n-gramを2に設定した場合、Generate sales、Sales forecast、Forecast reportがモデルの学習に使用されます。n-gramを3に設定した場合には、Generate sales forecastおよびSales forecast reportがモデルの学習に使用されます。
n-gramシーケンス長を使用してn-gramを設定することができます。n-gramの最小値はデフォルトで1になっています。 最大4まで設定することができます。 - Skip-gram – コーパスが非常に限られている場合や、トレーニング文の単語数が少ない場合は、一般的にSkip-gramの方が適しています。このためには、以下を定義する必要があります。
- シーケンス長 – Skip-gramシーケンスの長さで、最小値は2、最大値は4です。
- 最大スキップディスタンス – グラムを形成するためにスキップする最大単語数で、最小値は1、最大値は3です。
MLしきい値
インテントを一致の可能性のあるものとして認定するための最小MLスコアを定義します。MLスコアリングについての詳細をご確認ください。
NERモデル
エンティティ検出に使用するNERモデルを選択します。
エンティティのプレースホルダ
トレーニング音声内に存在するエンティティ値を、学習モデルの対応するエンティティプレースホルダに置き換えることを可能にします。
MLモデルのアップグレード
新しく作成されたBotはすべて、新しいMLモデルをデフォルトで使用します。開発者は、古いBotのMLモデルをアップグレードしたり、新しいモデルを使用してBotのモデルをダウングレードしたりすることができます。
Botプラットフォームで以前のモデルのMLを使用している場合は、以下の方法でアップグレードすることができます。
- MLモデルをアップグレードするBotを開き、自然言語 > 詳細設定に進みます。
- 機械学習を展開します。MLのアップグレードセクションで今すぐアップグレードボタンをクリックします。確認ウィンドウが開きます。
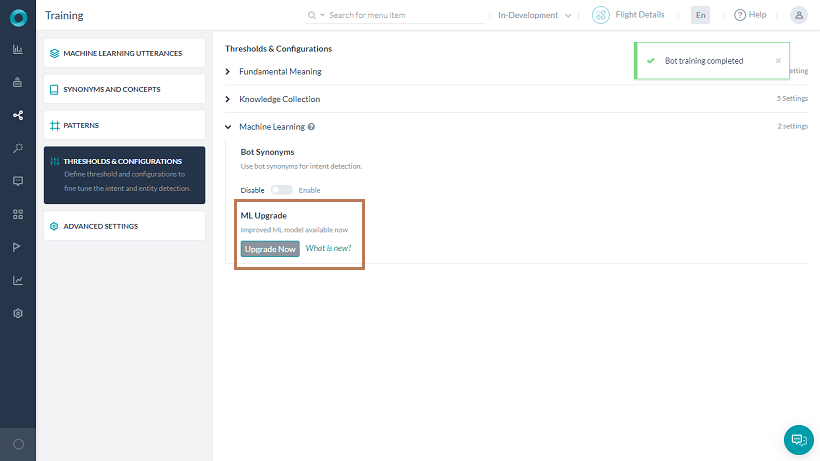
- アップグレードとトレーニングをクリックします。機械学習セクションの下に新しいカスタマイズ可能なオプションが表示されます。
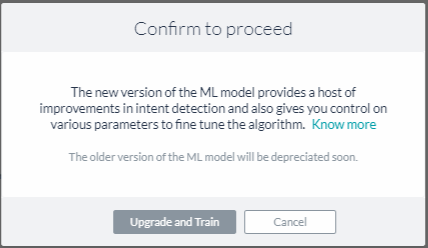
また、古いバージョンに置き換えるをクリックすると、MLモデルをダウングレードすることができます。ただし、古いバージョンのMLモデルはサポート終了となる可能性があることにご注意ください。継続的なサポートおよび今後の機能強化を受けるためには、最新版をご利用いただくことを強くお勧めします。
注:旧モデル(バージョン2)を使用してBotをエクスポートし、新しいBotとしてインポートした場合、アップグレードするまではバージョン2モデルのままです。[/vc_column_text][us_separator show_line="1"][vc_column_text]
機械学習の発話のエクスポートとインポート
BotのML発話をCSVやJSON形式で別のBotにインポートしたり、エクスポートしたりすることができます。エクスポートするタスクは「開発中」と「公開済み」のどちらかを選択することができますが、発話をインポートすると、Bot内のタスクの最新のコピーが常に置き換えられます。
ML発話のエクスポートまたはインポート方法
- Botのメニューで自然言語 > 機械学習の発話をクリックします。
- デフォルトではBotのML発話の「開発中」バージョンが表示されます。「公開済み」バージョンの発話を確認したい場合は、ウィンドウの右上にある公開済みに切り替えてください。
注:ML発話のエクスポートは、以下の「エクスポート済みの発話のバージョニングと動作」で説明されているように、この選択によって異なります。 - オプションアイコンをクリックして、オプションを選択します。
- インポートをクリックして、インポートする発話を含むCSVファイルまたはJSONファイルをアップロードします。詳細については、インポート済みの発話のバージョニングと動作のセクションを参照してください。
- エクスポートをクリックし、CSV形式またはJSON形式を選択して発話をエクスポートします。詳細については、以下のエクスポート済みの発話のバージョニングと動作のセクションを参照してください。
インポート済みの発話のバージョニングと動作
- インポートされたCSV/JSON形式の発話は、タスクの最新のコピーに存在する発話に、完全に置き換えられます。
- タスクが設定済みステータスになっている場合、タスク内の発話は、インポートされたファイルに存在するタスクの新しい発話に、完全に置き換えられます。
- タスクが進行中のアップグレードのステータスになっている場合、タスクに関連する発話は、インポートされたファイルに存在するタスクの発話に完全に置き換えられます。タスクの公開済みコピーの発話は影響を受けません。
- タスクが公開済みのステータスになっている場合、タスクの進行中のアップグレードのコピーがデフォルトで作成され、インポート済みファイルに存在する新しい発話がアップグレードされたコピーに追加されます。タスクの公開済みのコピーの発話は影響を受けません。
エクスポート済みの発話のバージョニングと動作
- Botの発話をエクスポートすると、アラート、アクション、情報、ダイアログなど、すべてのタスクタイプに関連するすべての発話がエクスポートされます。
- Botの開発中コピーをエクスポートすると、最新の利用可能なコピー内にあるすべてのタスクの発話がエクスポートされます。
- Botの公開済みのコピーをエクスポートすると、公開済みになっているすべての発話がエクスポートされます。
- 多言語Botの場合、発話のエクスポートは選択したBotの言語に対してのみ行われます。
- 発話のJSONへのエクスポートにはタスクに存在するNERタグが含まれていますが、CSVエクスポートには含まれていません。
MLトレーニングの推奨事項
- ボットが検出する必要があるすべての意図に対して、バランスのとれた訓練を与え、ほぼ同じ数のサンプル発言を追加します。偏向したモデルは偏向した結果をもたらす可能性があります。
- それぞれのインテントに対して少なくとも8~10のサンプル発話を提供します。発話の数が1~2しかないモデルでは、機械学習の効果は得られません。発話は多様なものにし、同じ単語を異なる順序で使用するような発話は提供しないようにします。
- 例えば「I want to」など、すべてのインテントに適用される可能性のある一般的なフレーズはトレーニングしないようにします。より多くの多様性と学習のために、発話を変化させるようにします。
- 変更のたびに、モデルをトレーニングし、モデルのチェックを行います。MLモデルのすべてのドットが対角(真正および真負)象限であり、他の象限に散在する発話がないようにします。これが達成されるまでモデルをトレーニングします。
- 新しい発話でBotを定期的にトレーニングします。
- 失敗した発話または放棄された発話を定期的に見直し、有効なタスクやインテントに照らし合わせて発話リストに追加します。
NLPインテント検出トレーニングの推奨事項
- 発話のサンプル数が多い場合は、ファンダメンタルミーニングモデルをトレーニングしようとする前に、まず機械学習のアプローチを使用してBotをトレーニングしてみます。
- Botの同義語を定義して、パスワード用のpwd 、普通預金口座用のSBなどのドメイン辞書を作成します。
- モデルのトレーニングを変更するたびに、バッチテストモジュールを実行します。テストスイートは、BotのMLモデルの回帰テストを実行するための手段です。
NLPエンティティ検出トレーニングの推奨事項
エンティティをトレーニングするための最良のアプローチは、以下に説明するように、エンティティの種類によって異なります。
- List of Items(列挙、ルックアップ)、City、Date、Countryのようなエンティティタイプは、同じエンティティタイプが同一タスク内において複数のタイプで使用されない限り、トレーニングの必要はありません。Botタスクで同一のエンティティタイプが使用されている場合は、トレーニングモデルのいずれかを使用して、ユーザーの発話の中からエンティティを見つけます。
- エンティティのタイプがStringまたはDescriptionの場合、エンティティパターンおよび同義語を使用することが推奨されます。
- その他すべてのエンティティタイプについては、NERとパターン両方を組み合わせて使用することができます。
エンティティトレーニングの推奨事項
- 可能な限りNERトレーニングを使用する – NERはパターンよりもバレッジが高くなります。
- NERアプローチは、情報がフォーマットされていないデータとして提供されるエンティティの検出に最適です。日付や時刻のようなエンティティについては、プラットフォームは大規模なデータセットを用いてトレーニングされています。
- NERはニューラルネットワークベースのモデルであり、効果的に動作させるためには少なくとも8~10のサンプルを用いてトレーニングする必要があります。